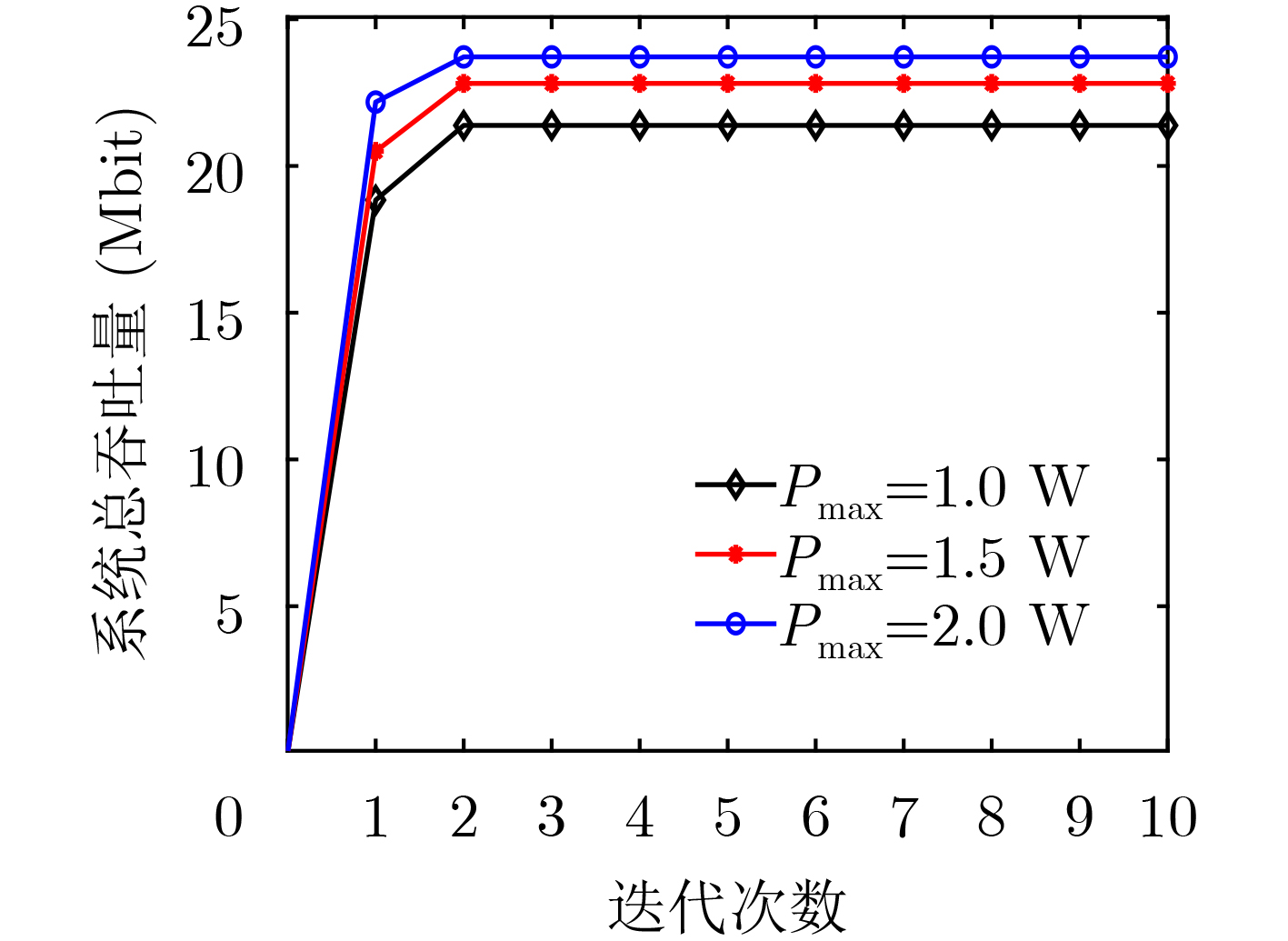
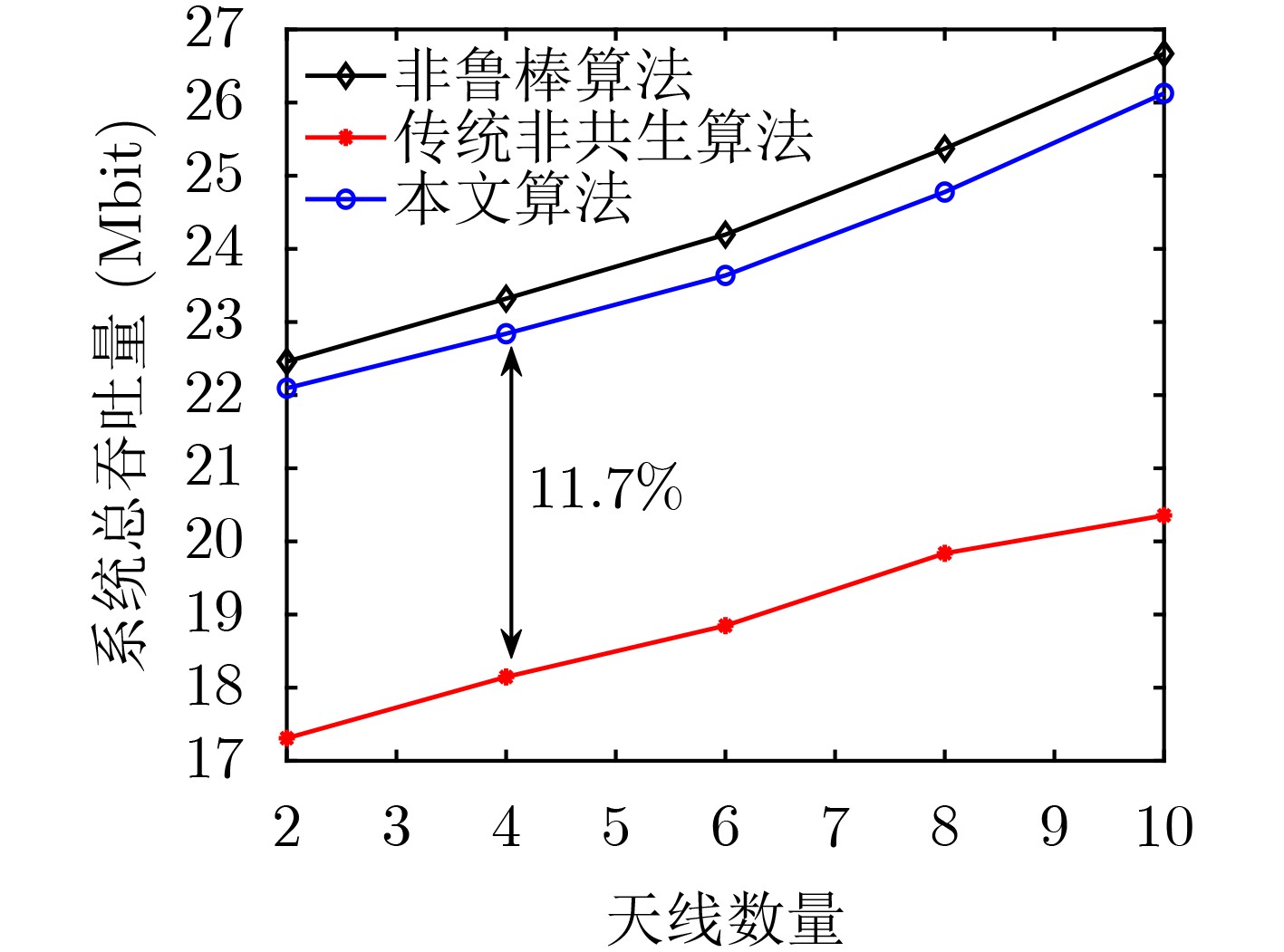
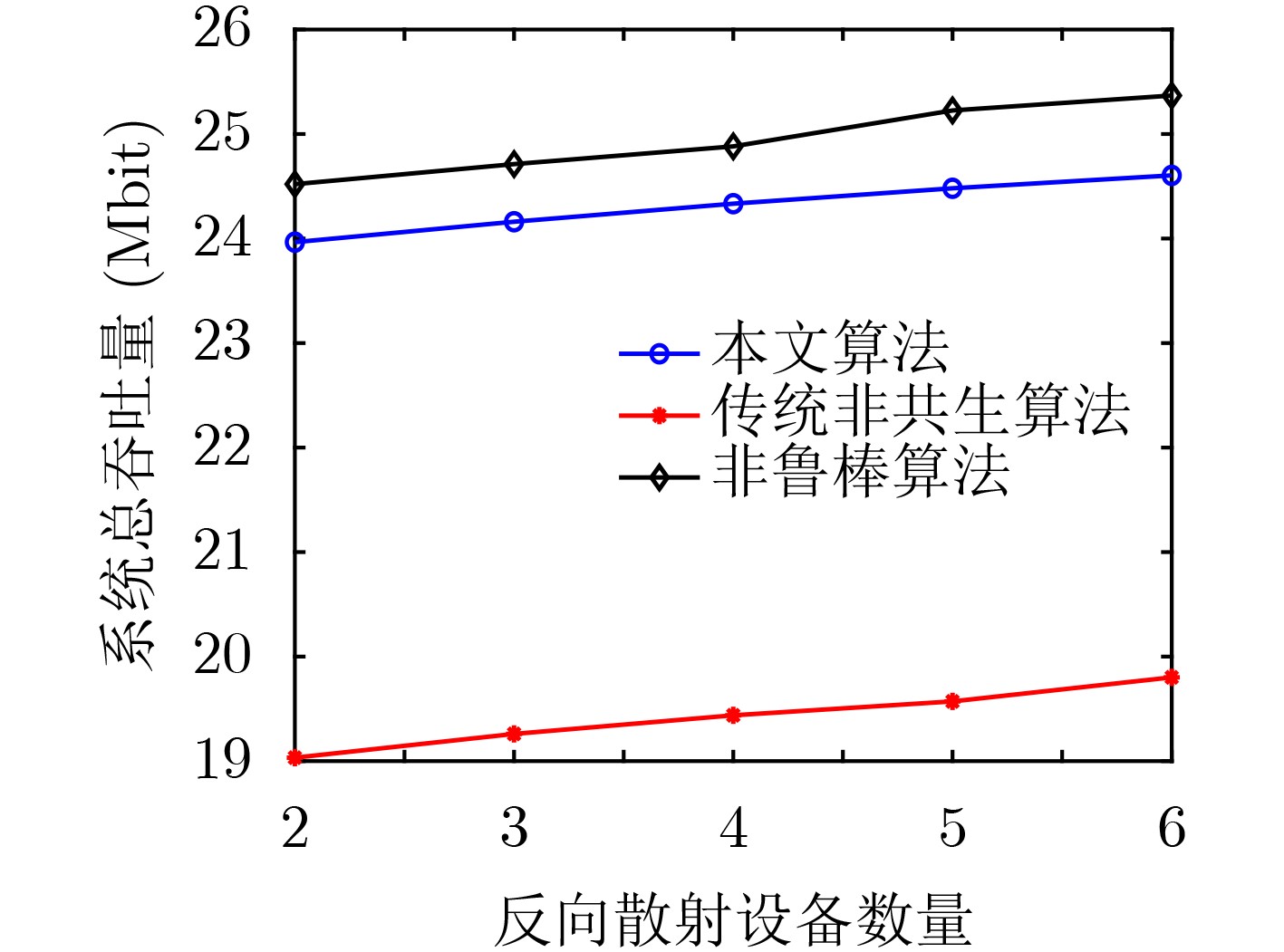
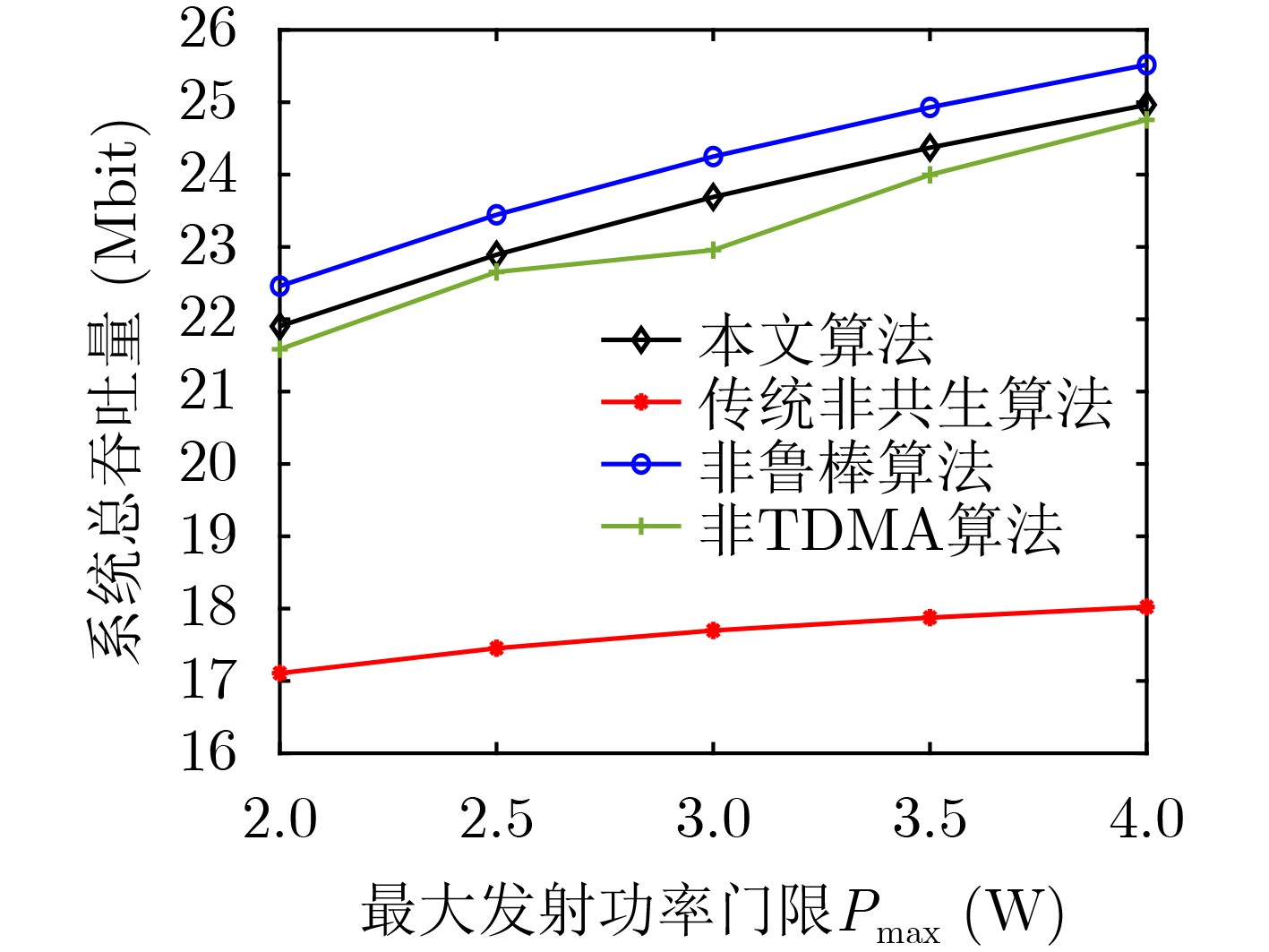
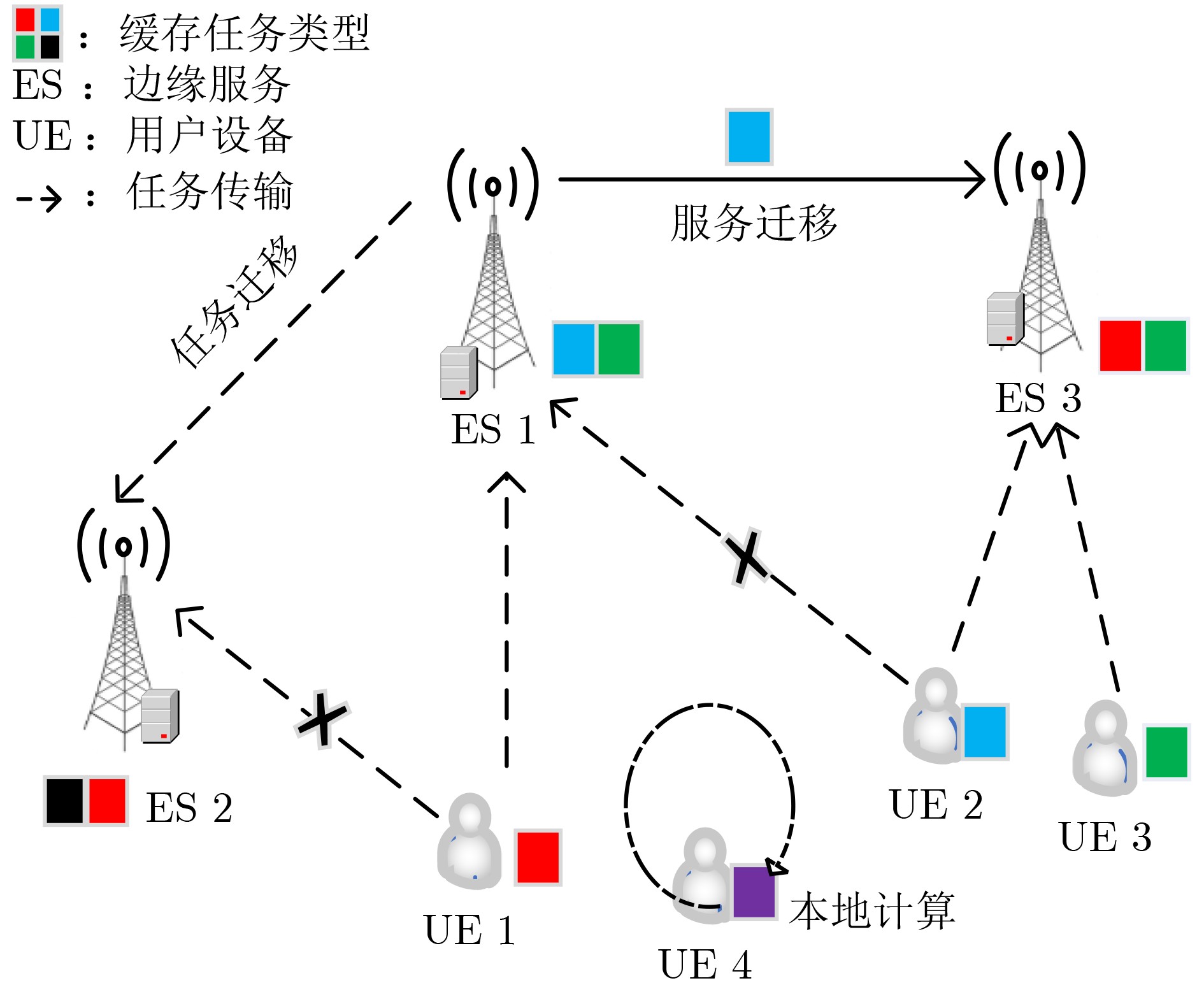
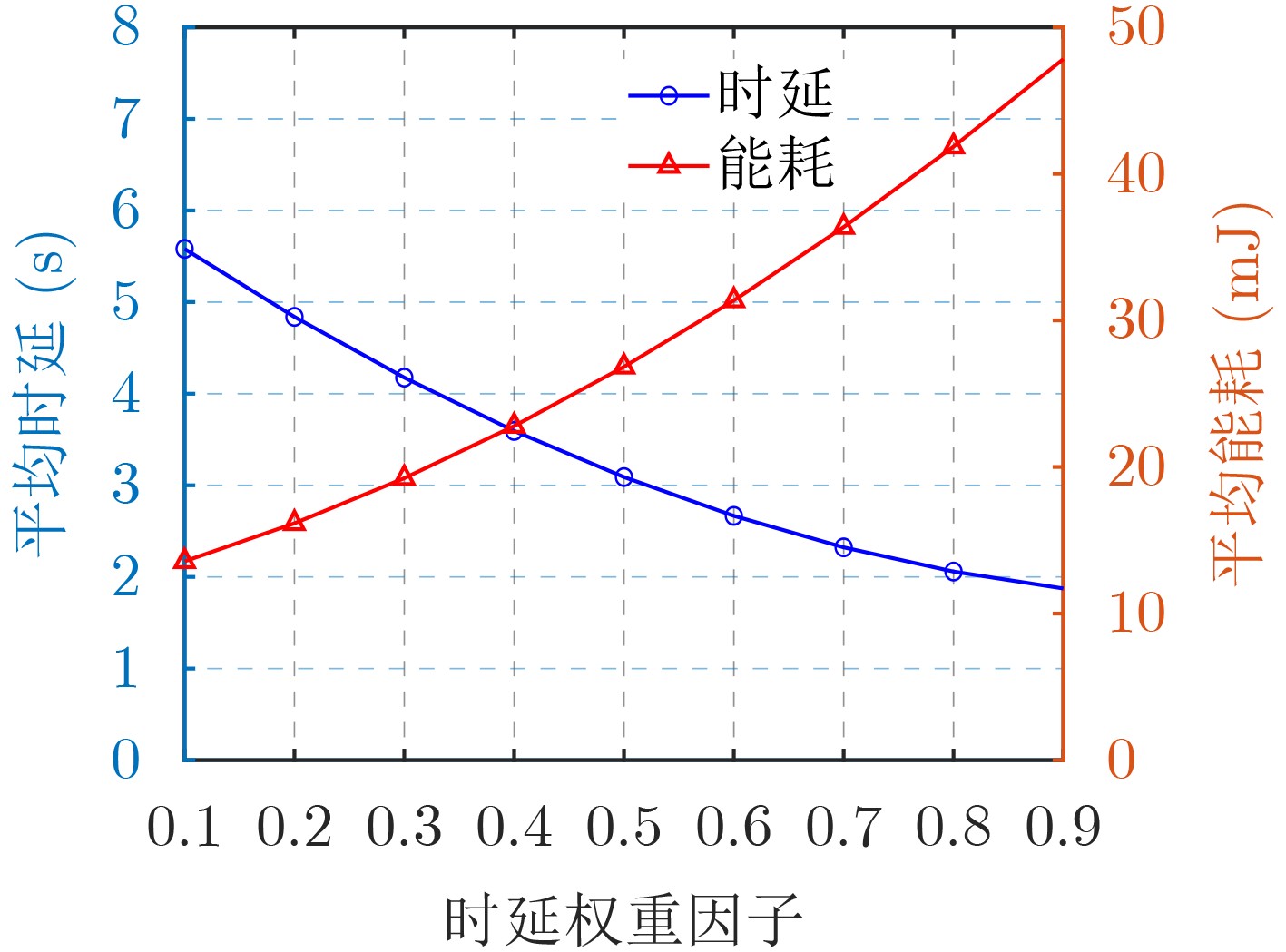
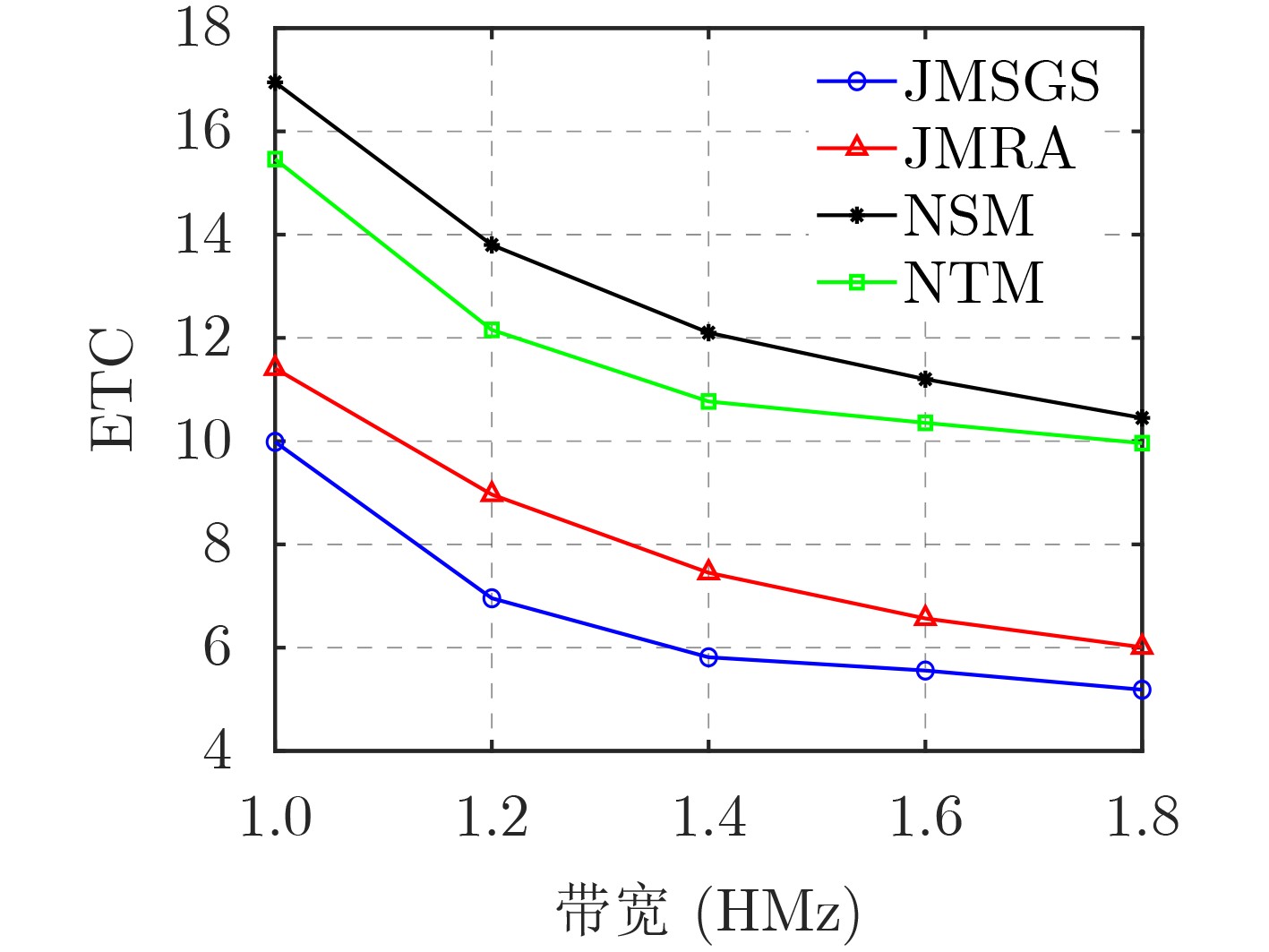
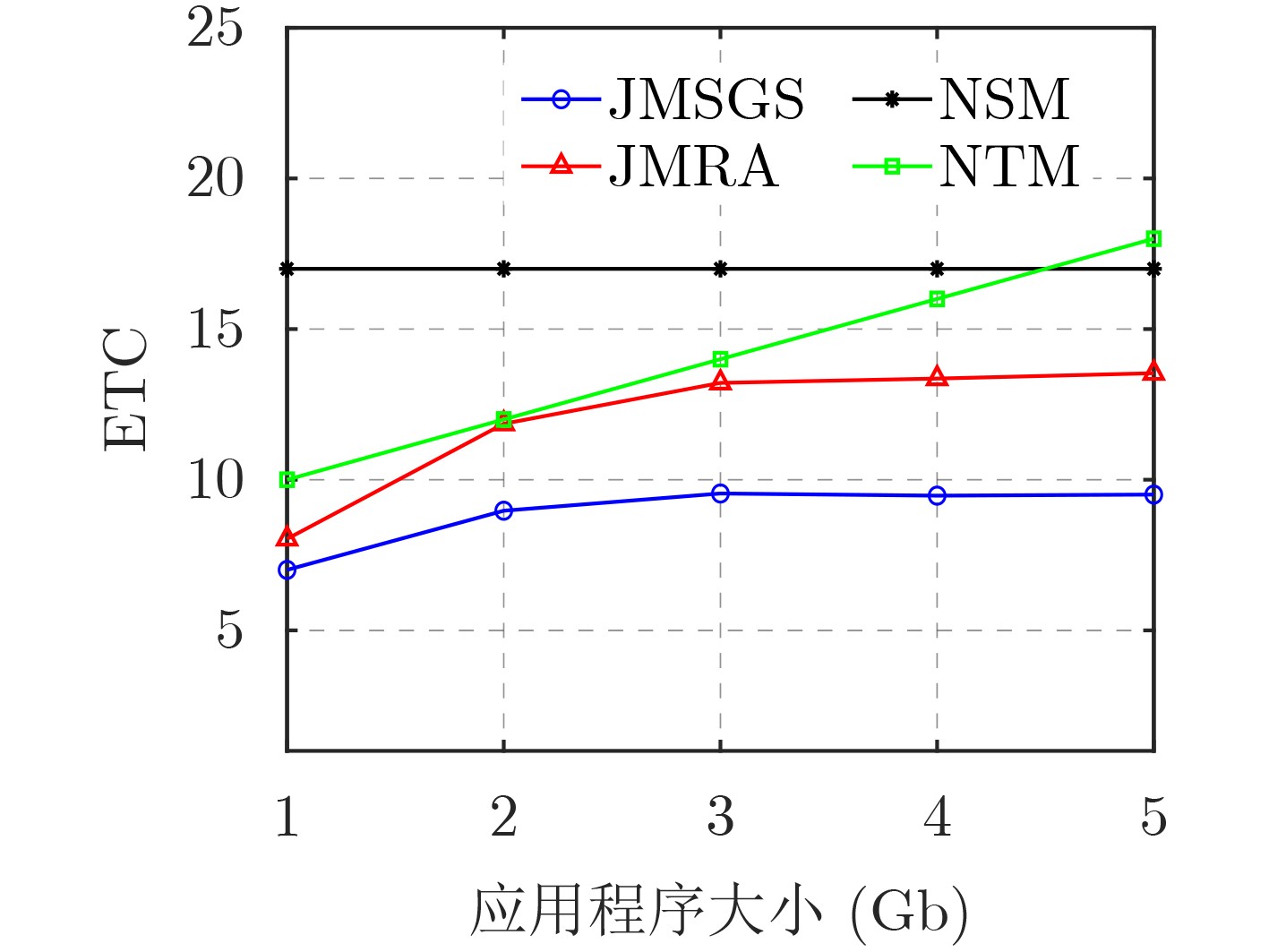
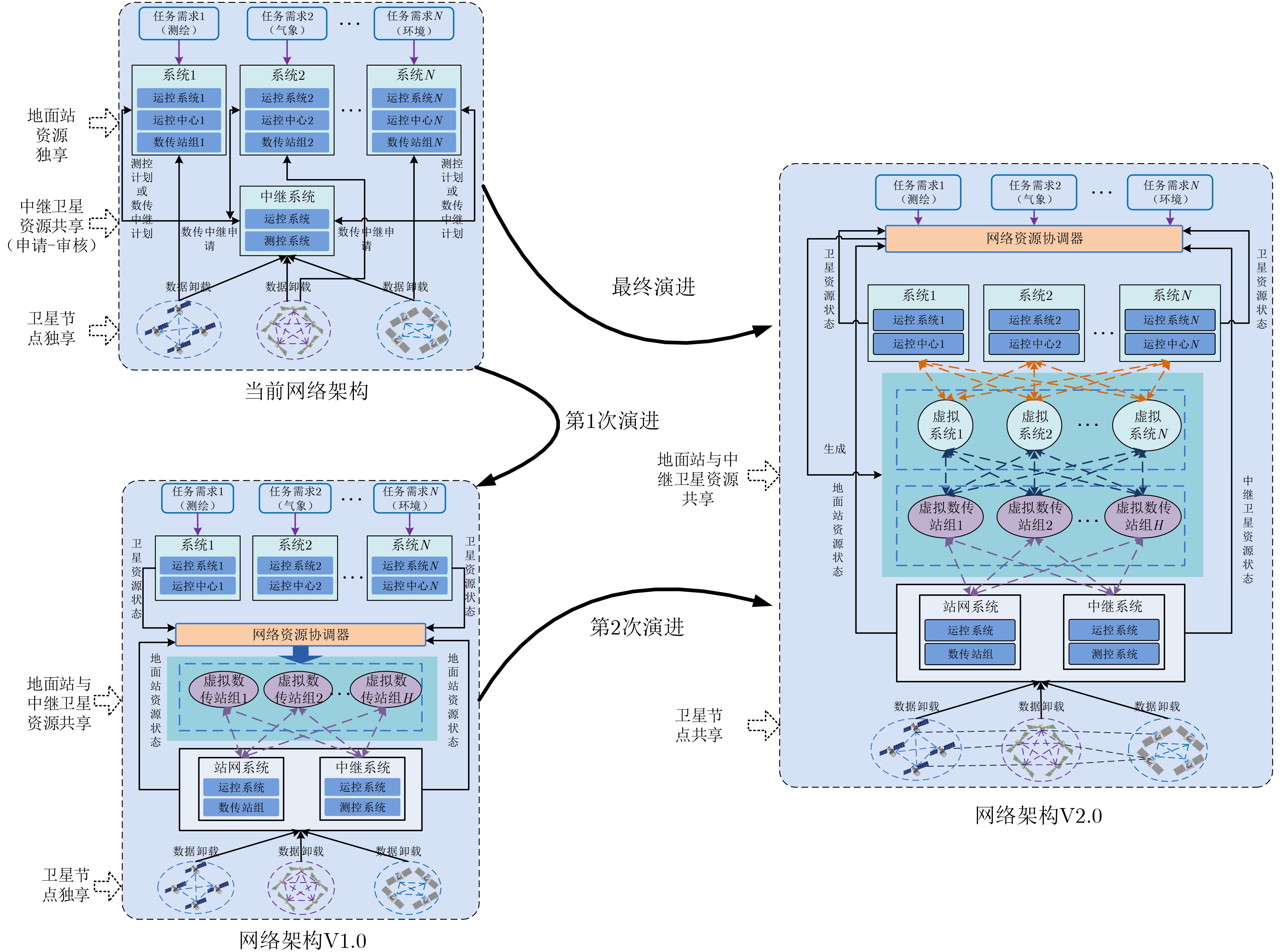
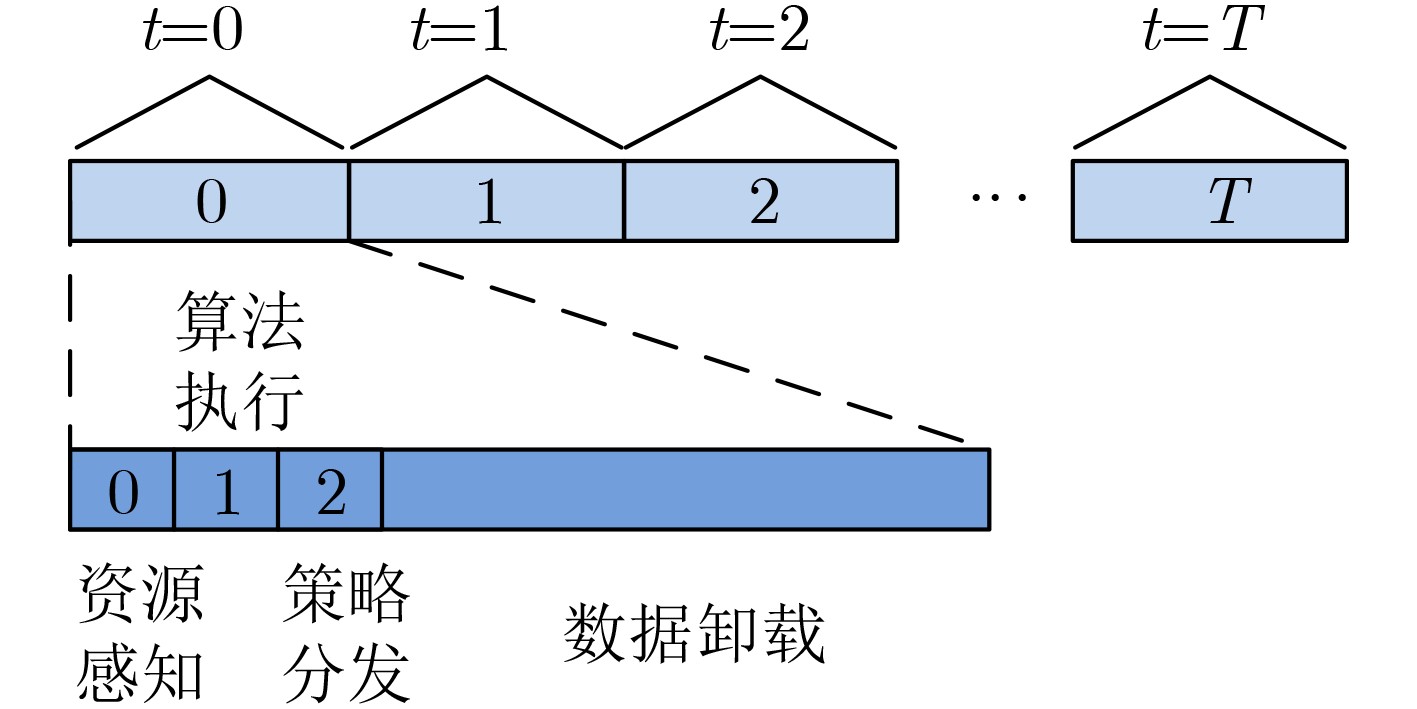
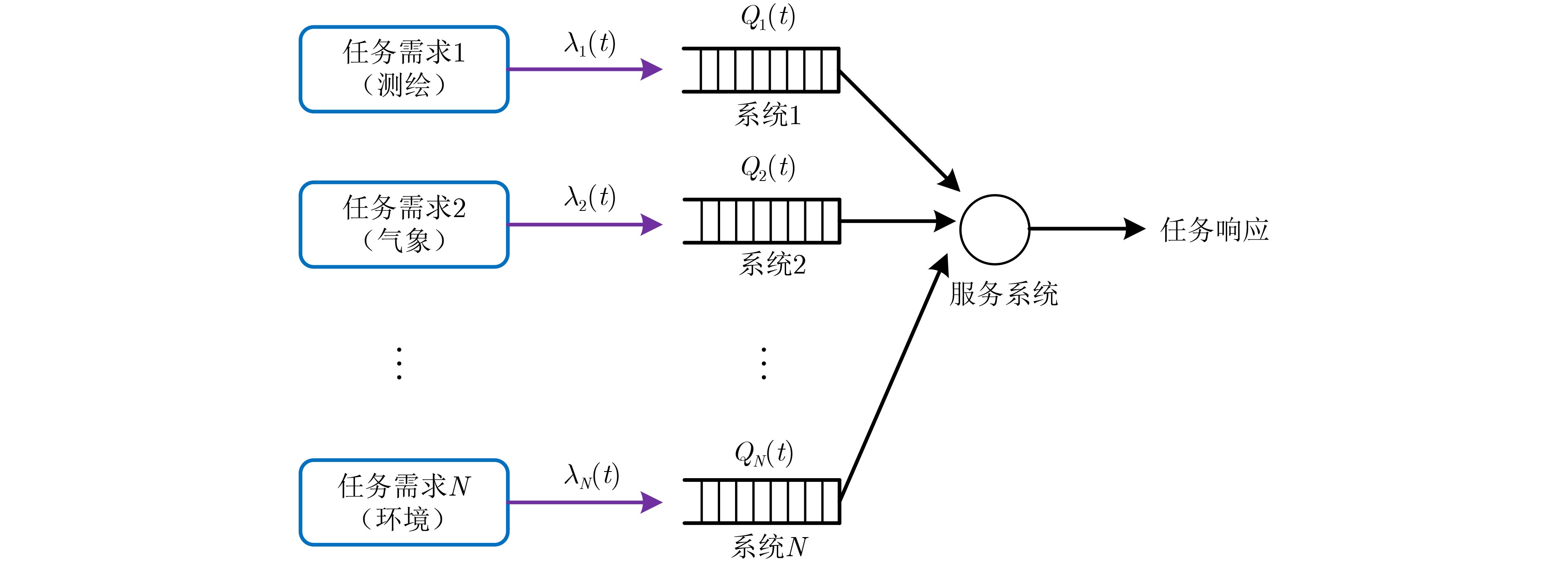
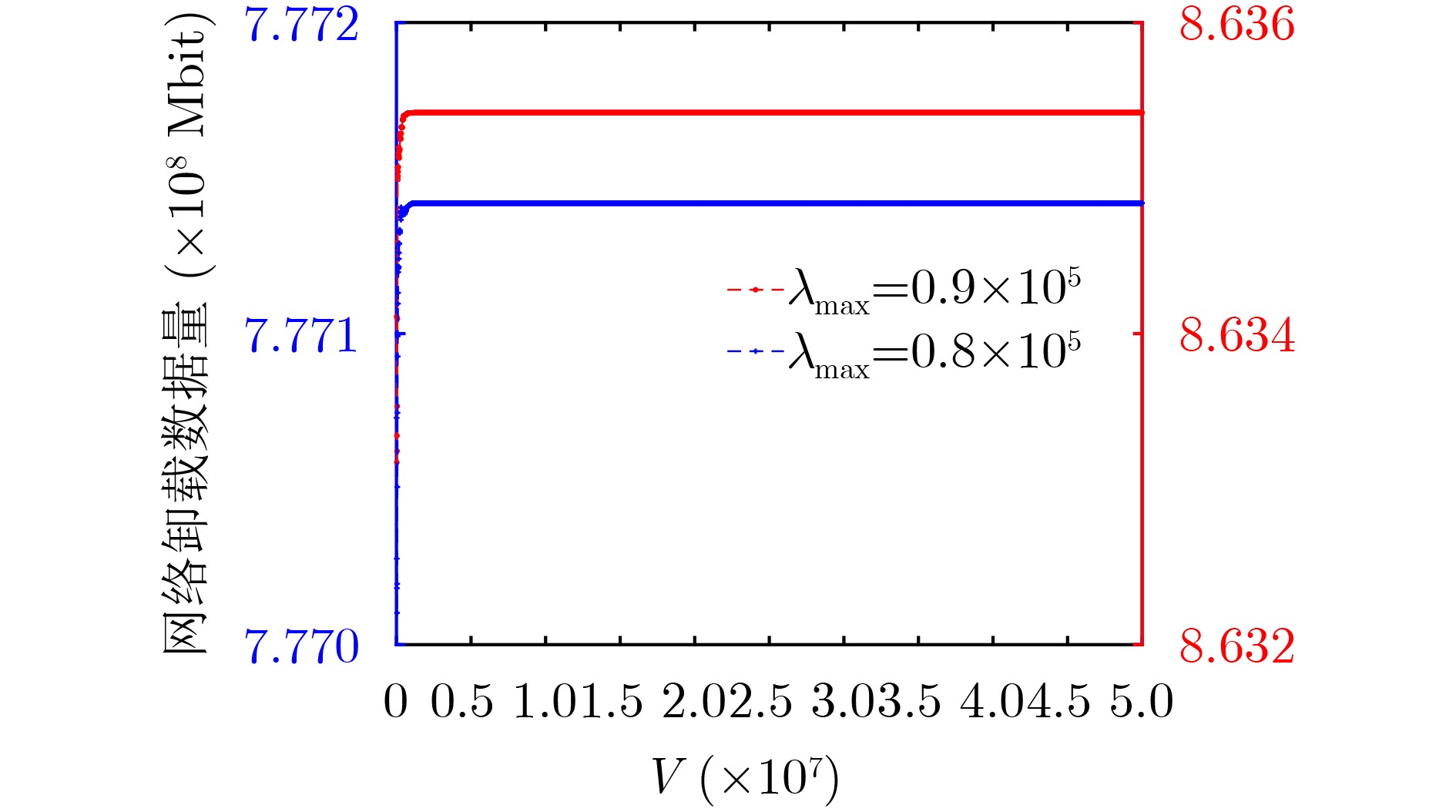
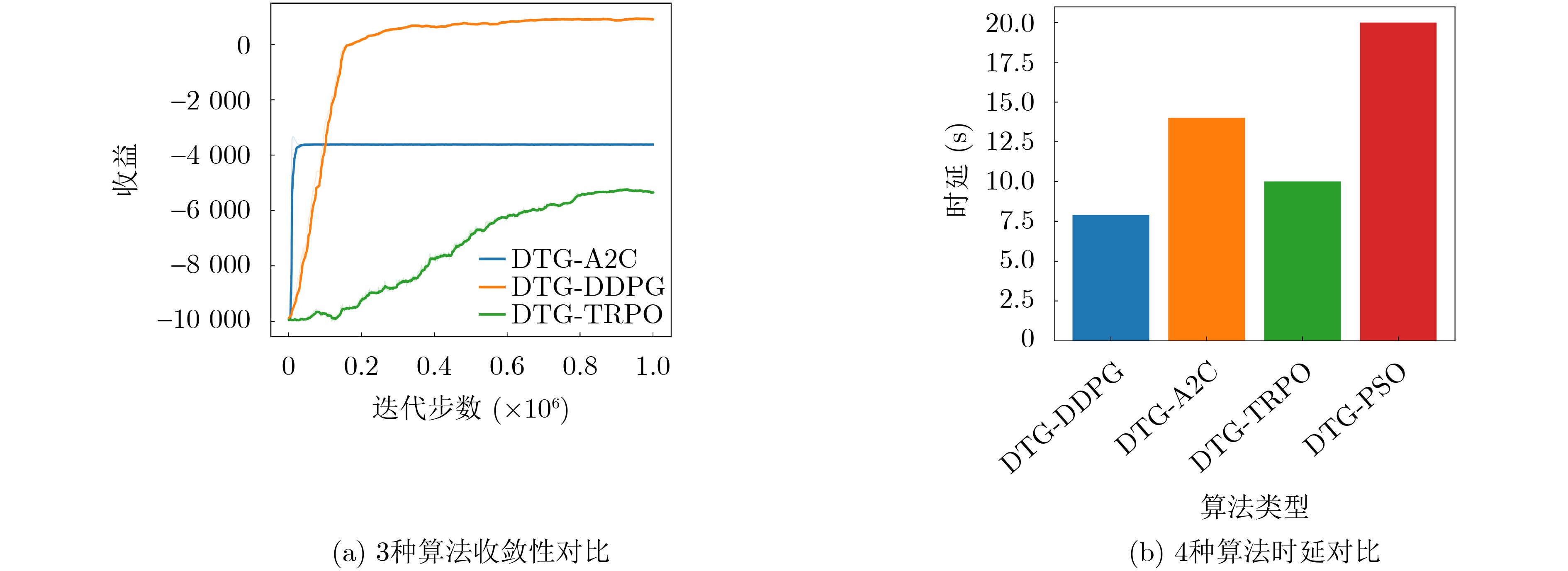
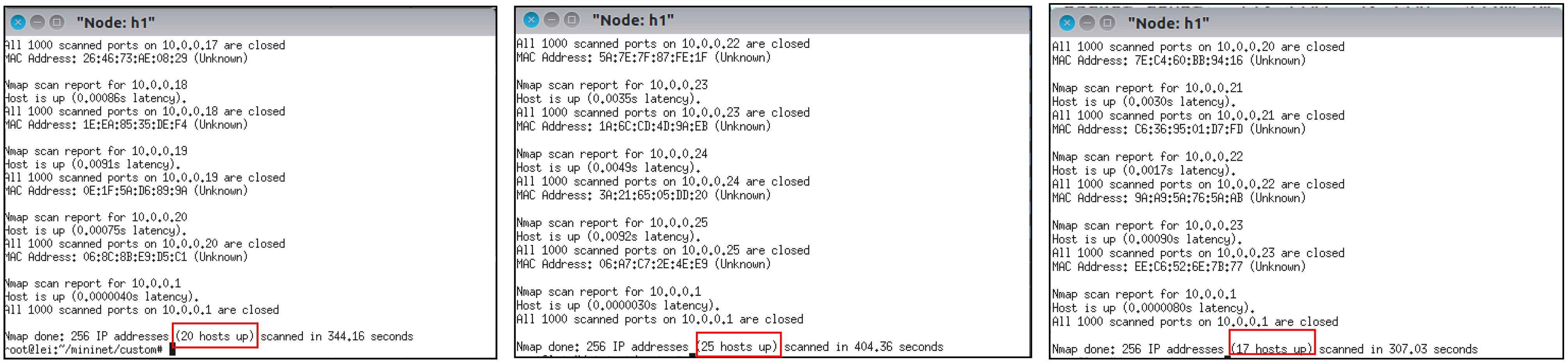
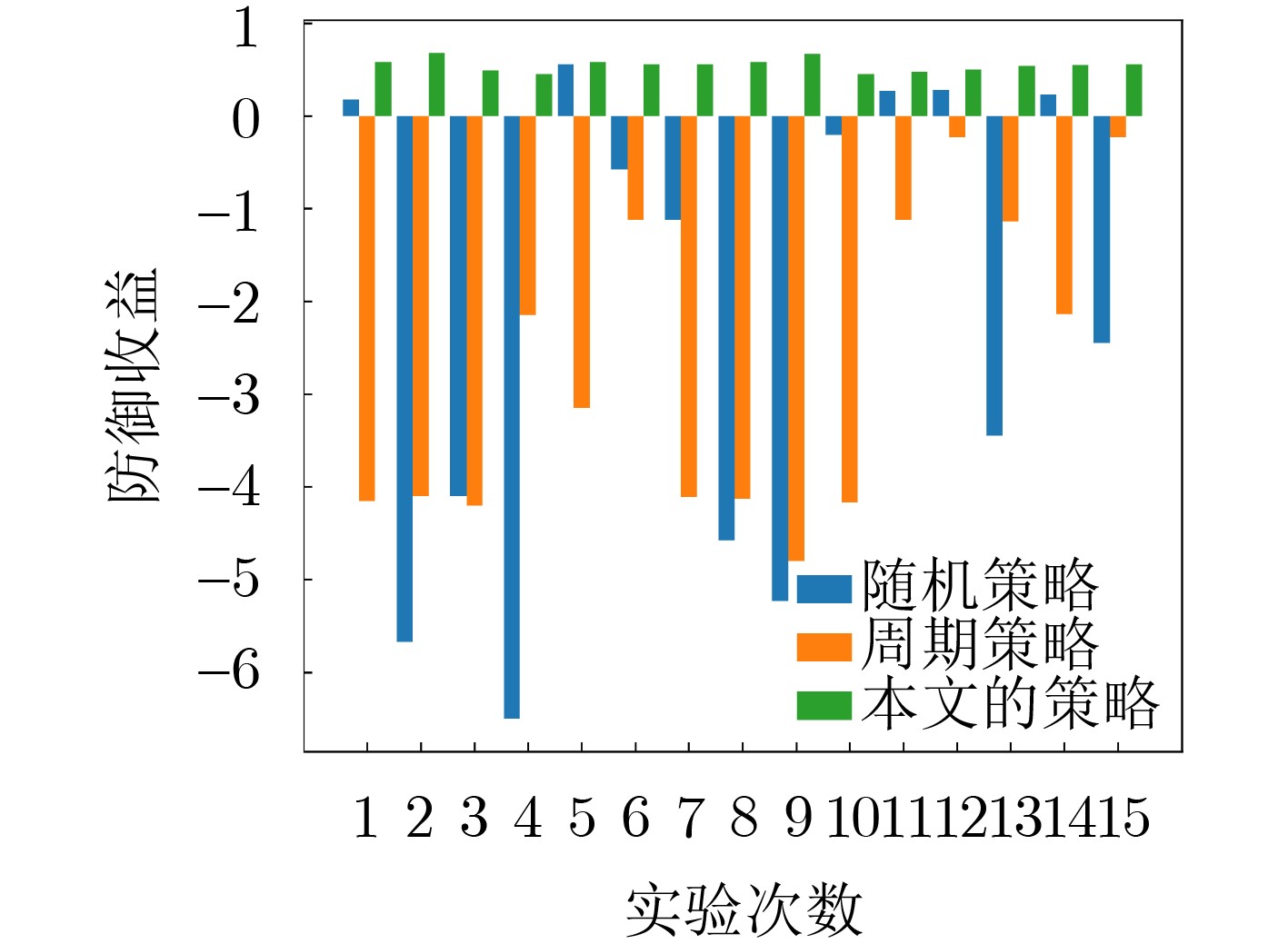
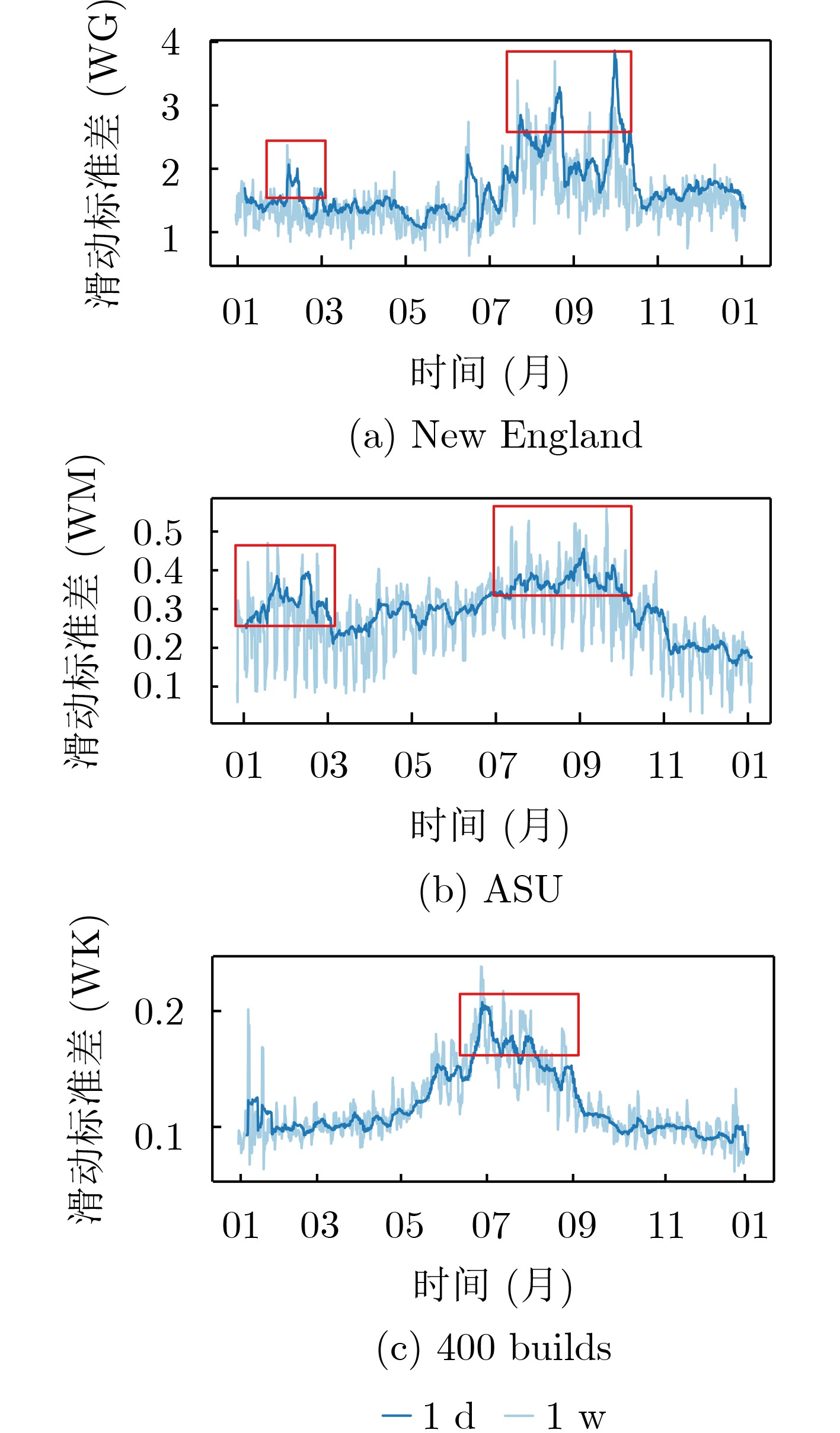
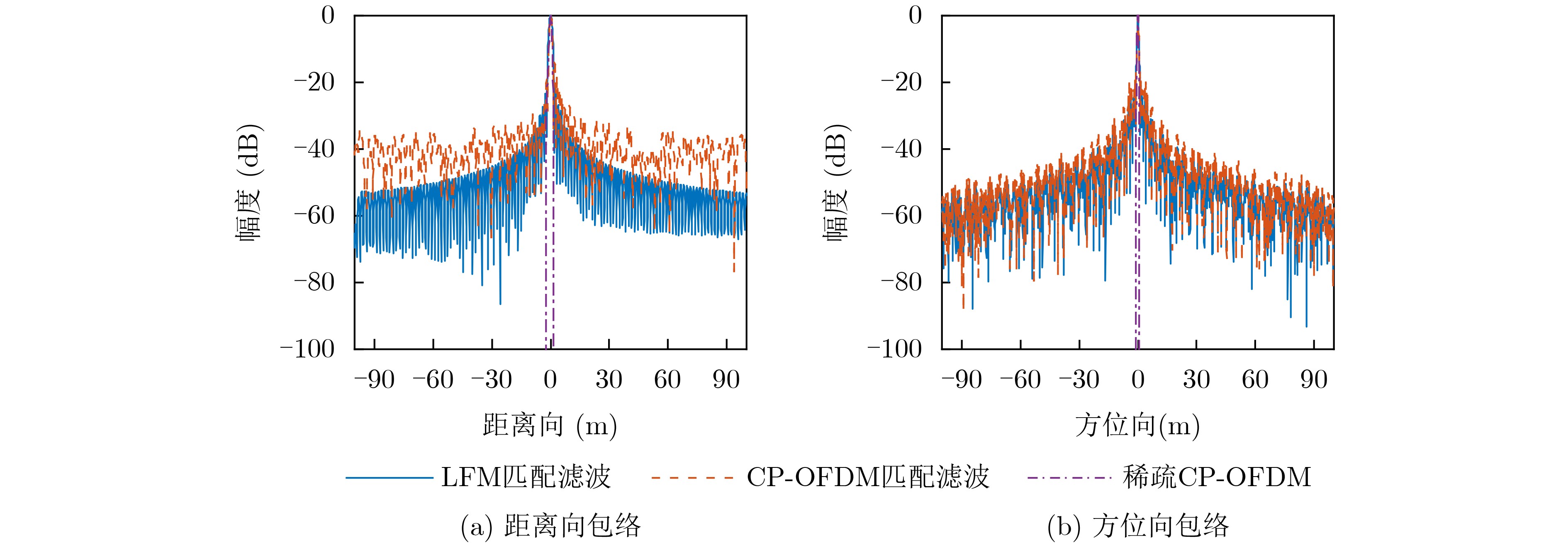
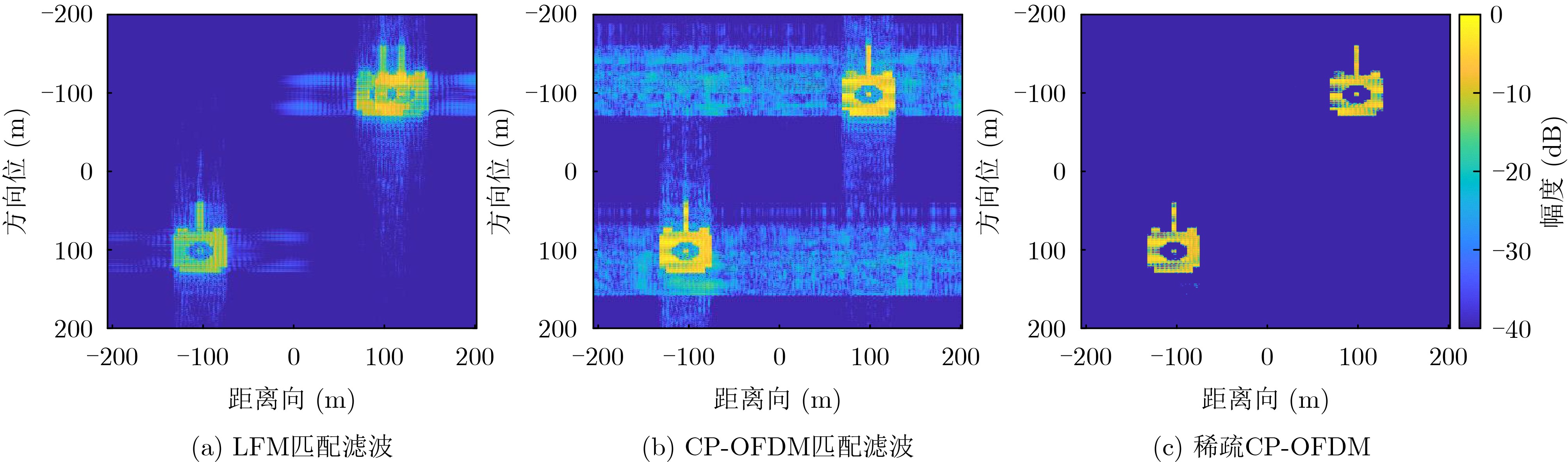
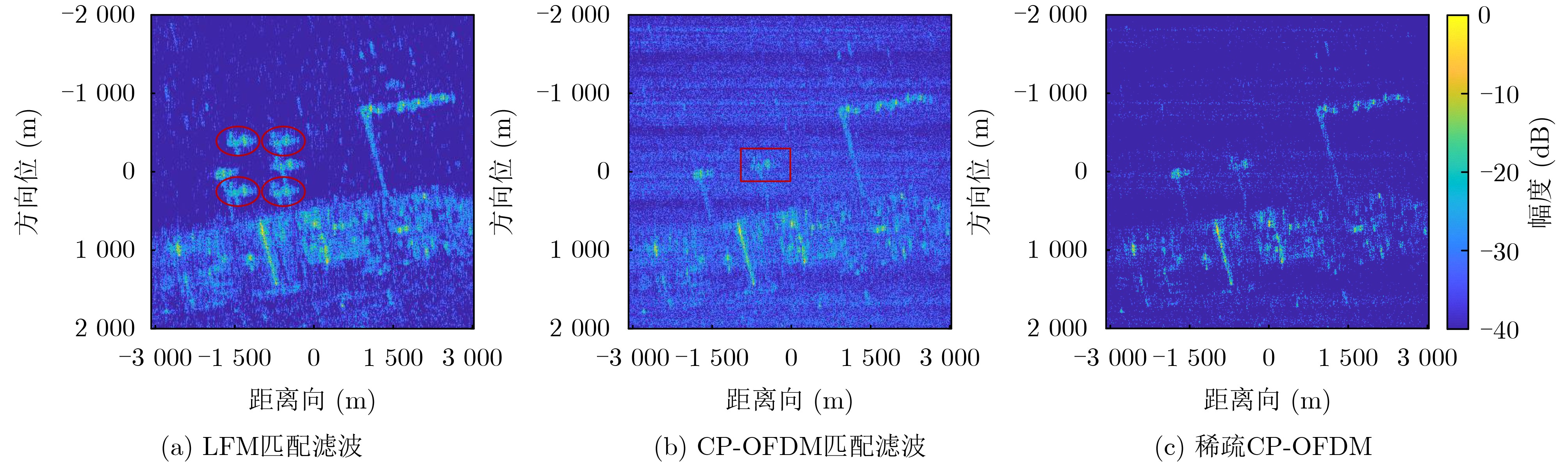
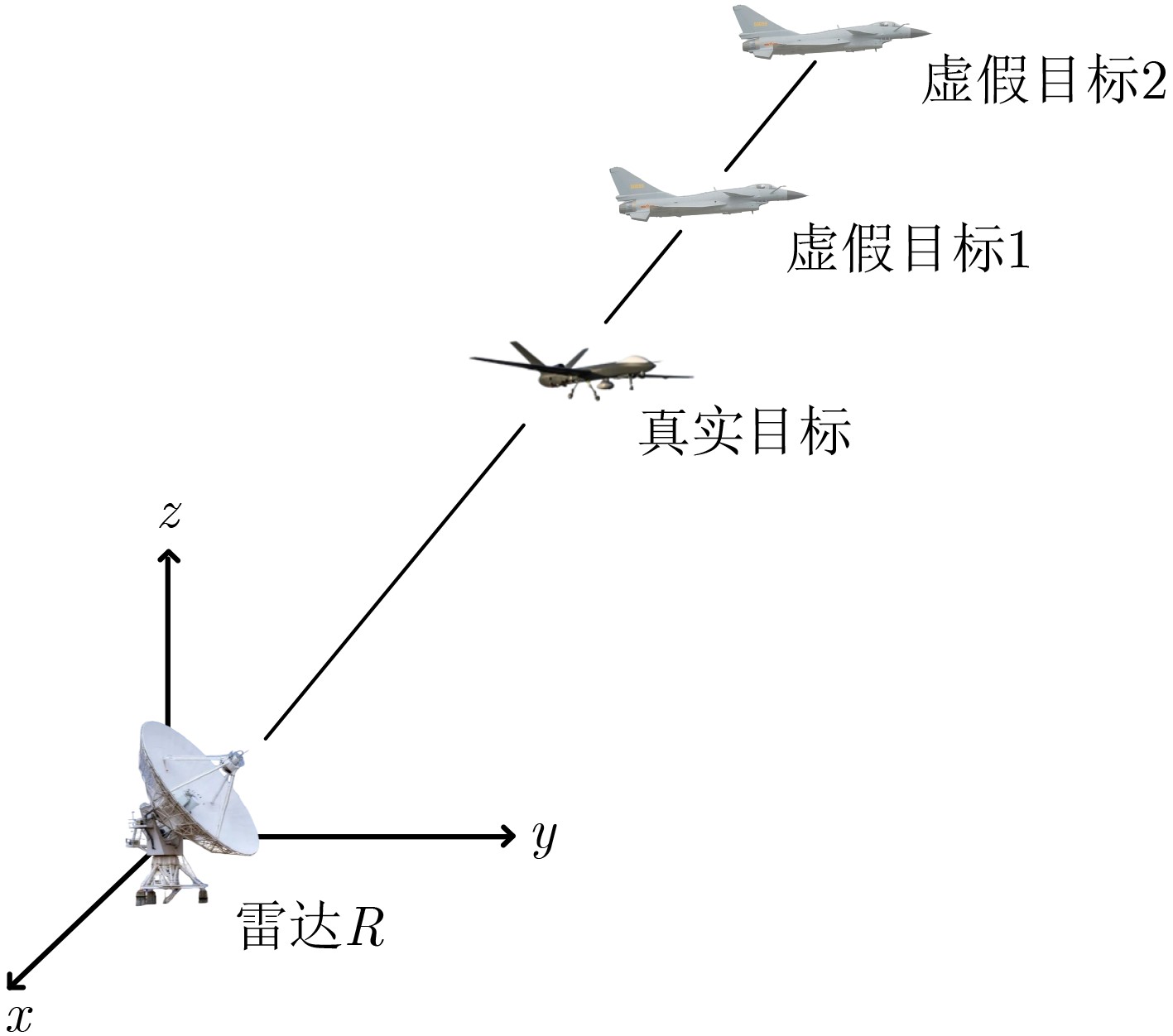
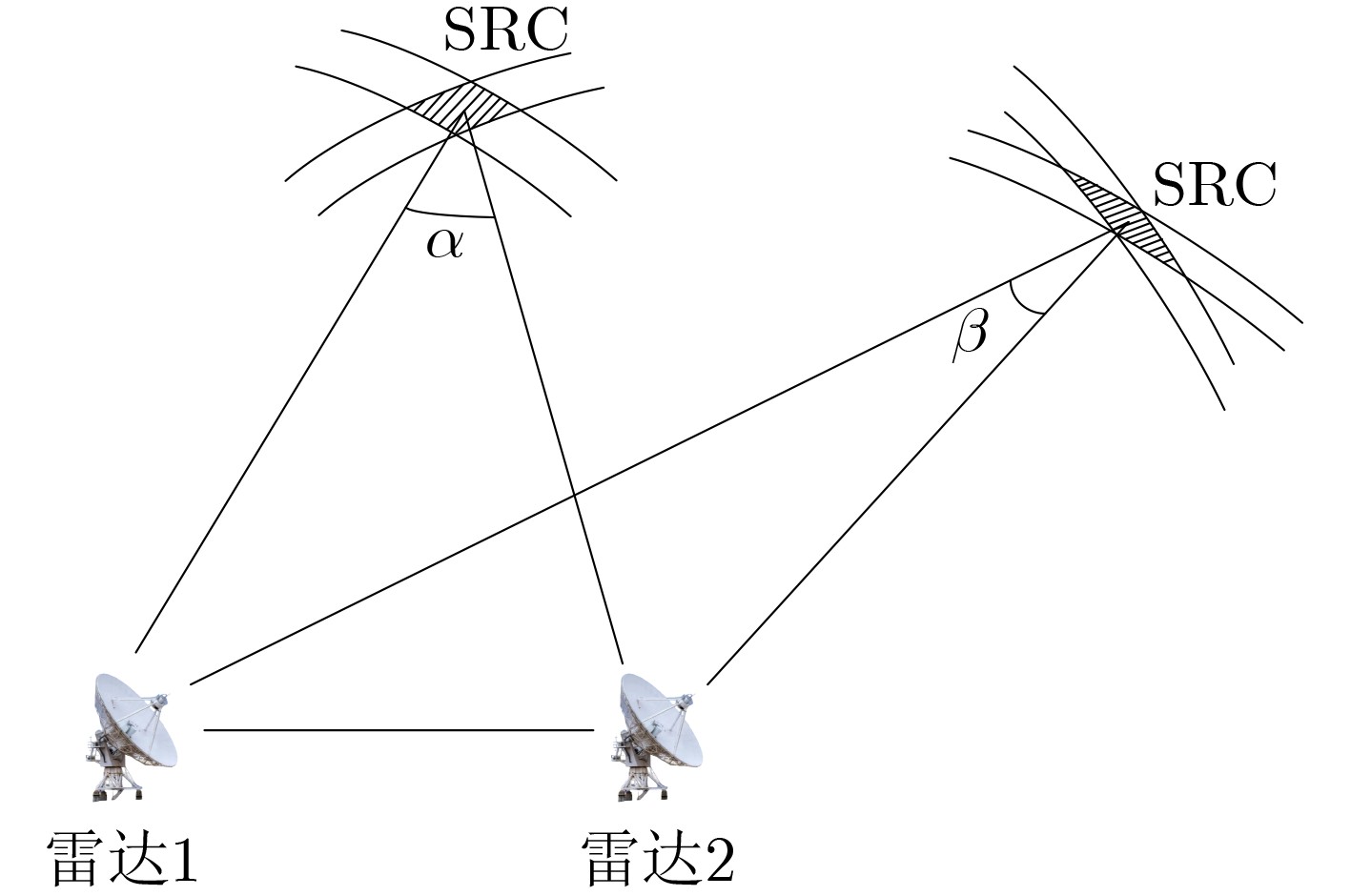
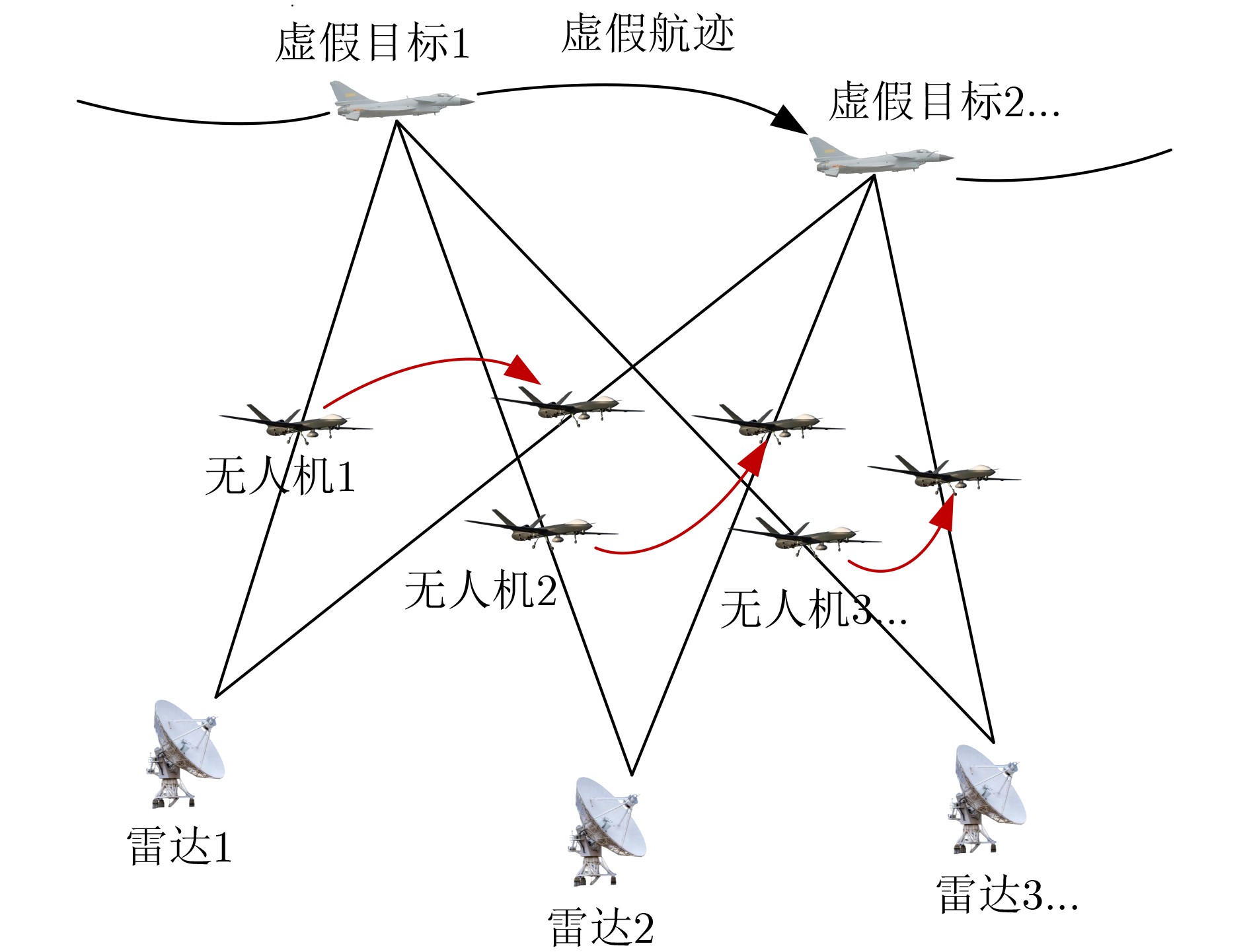
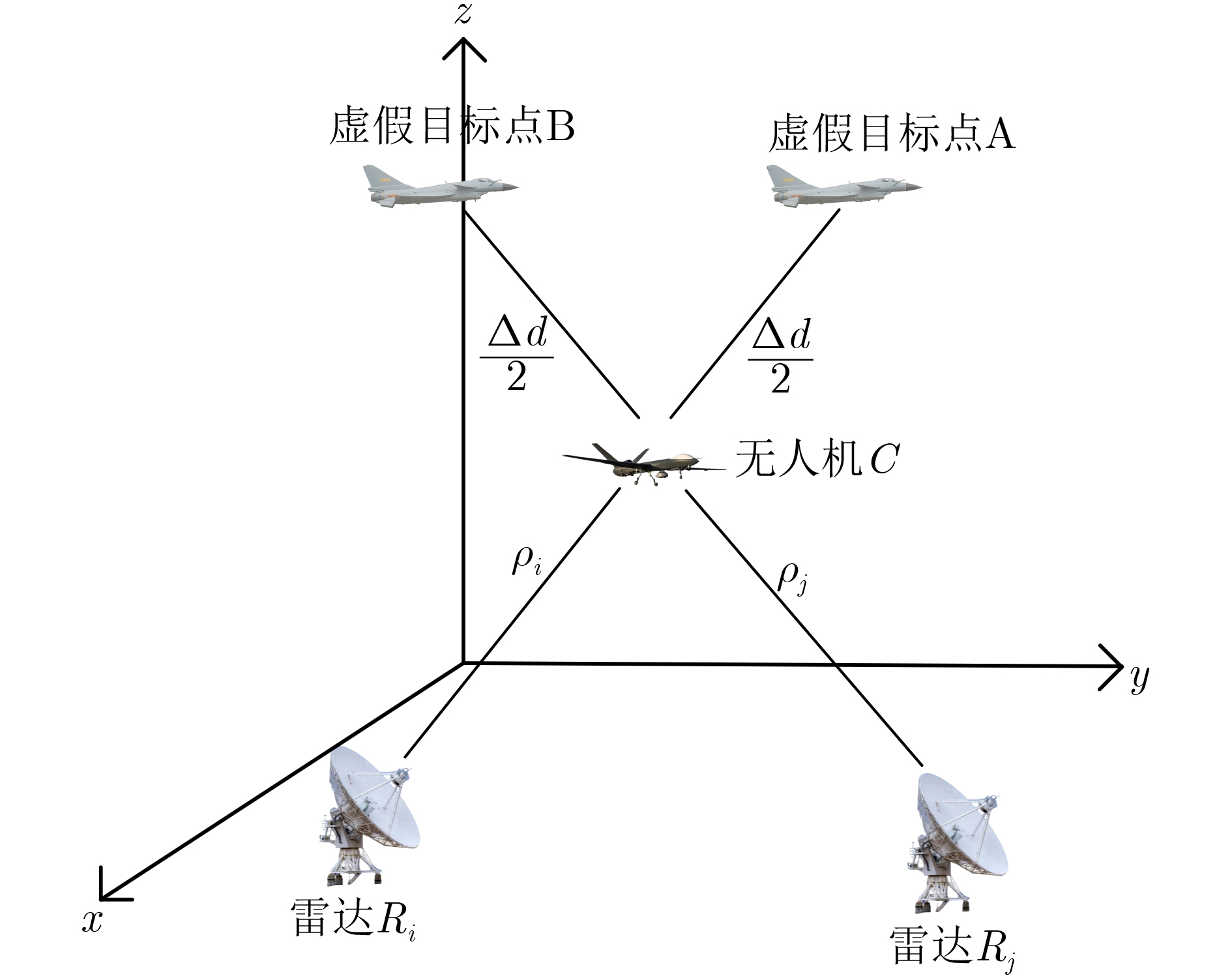
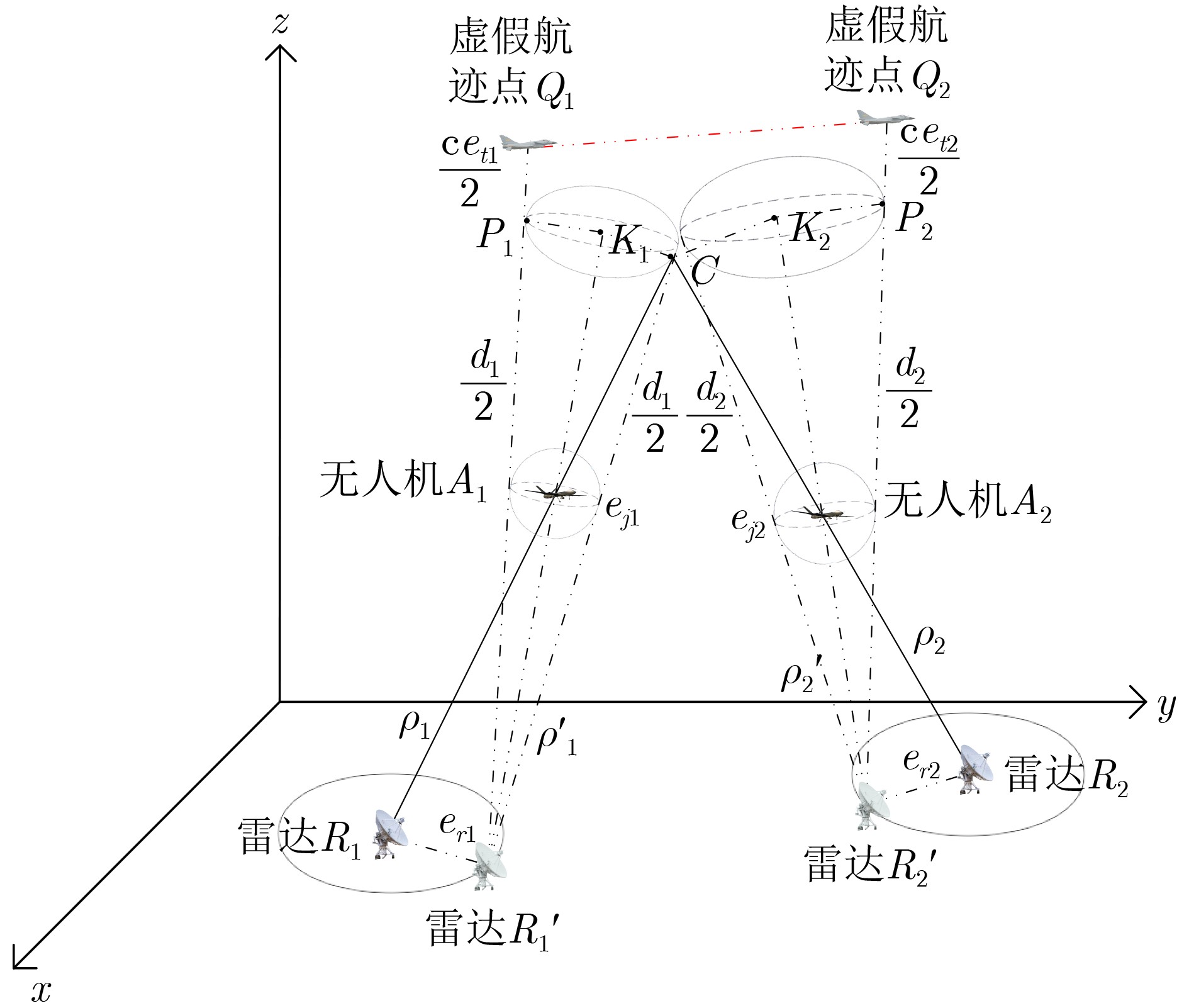
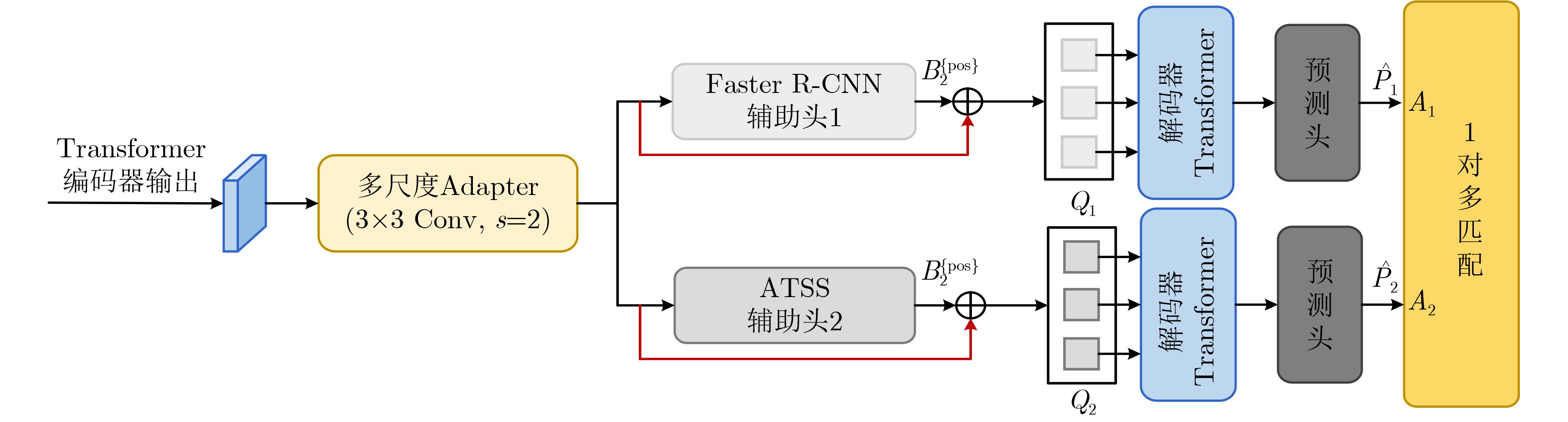
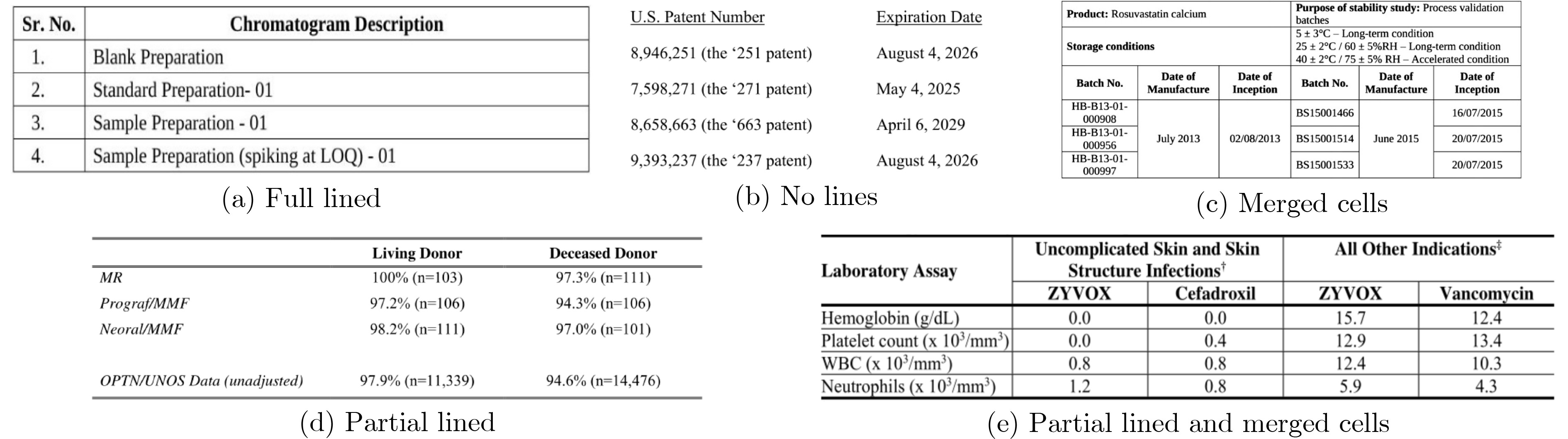
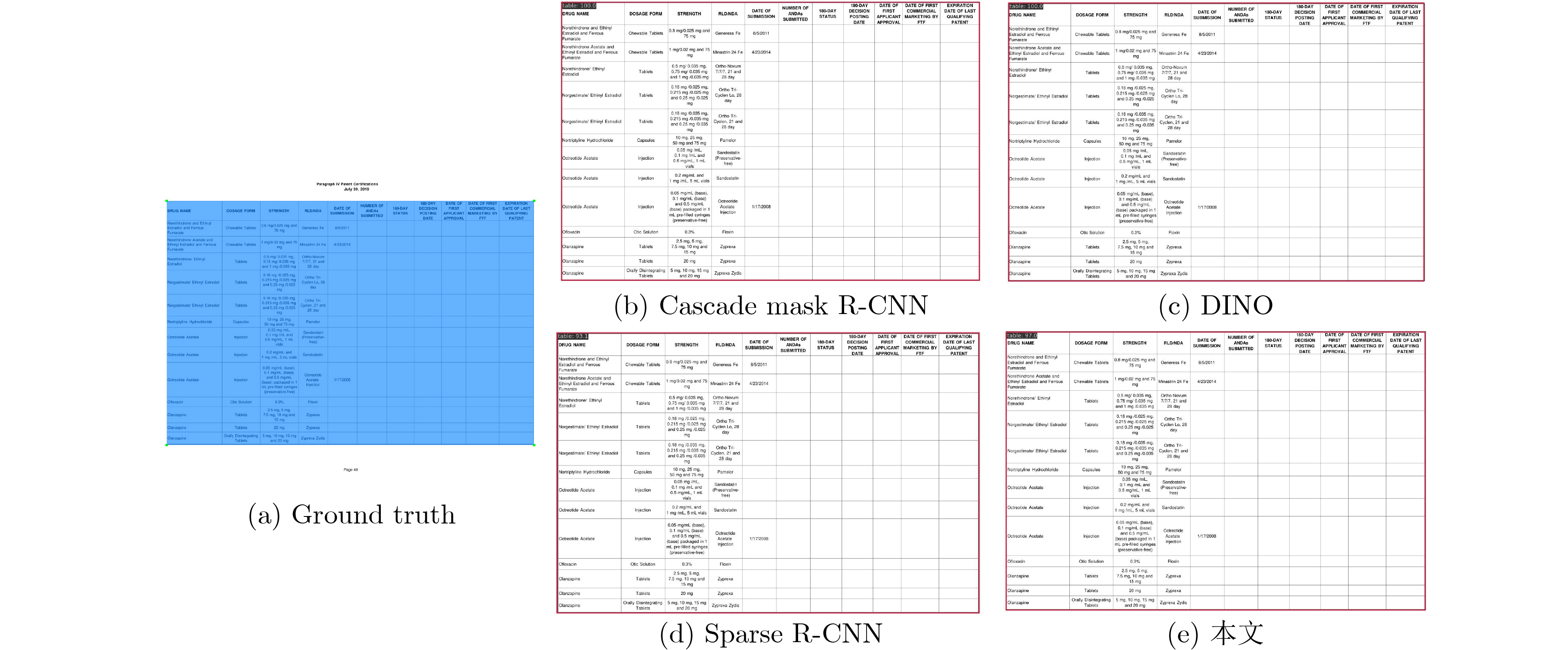
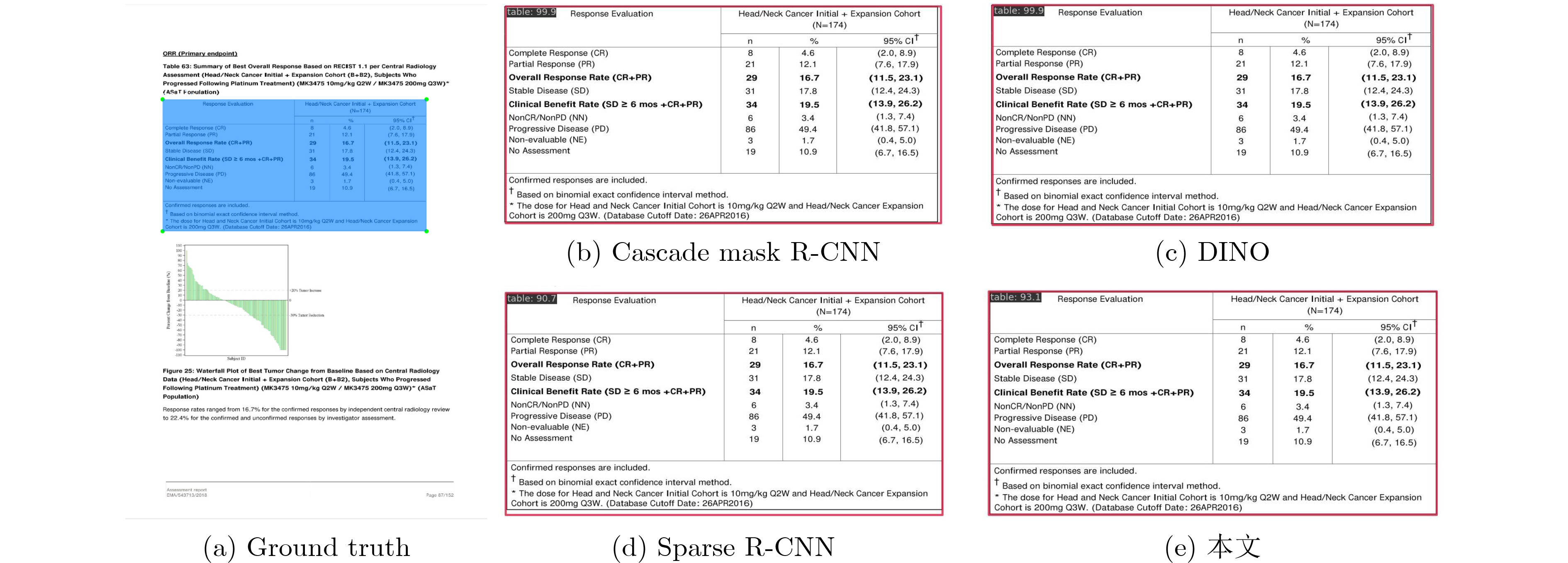
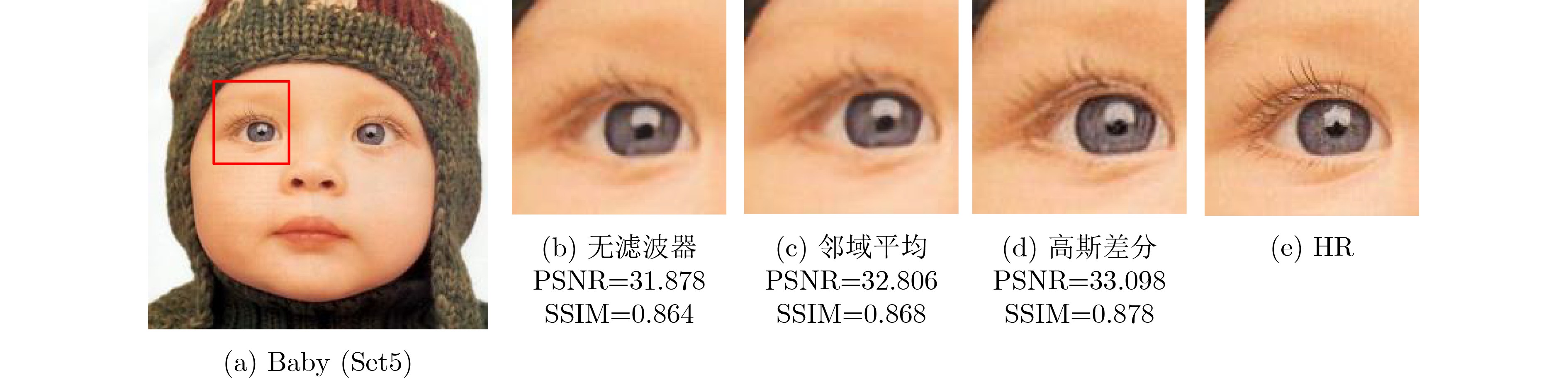
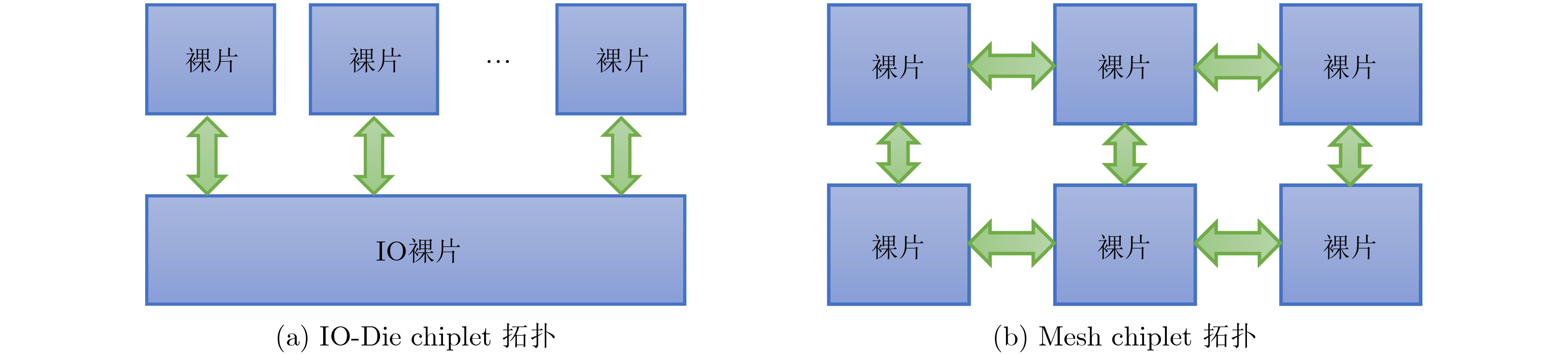
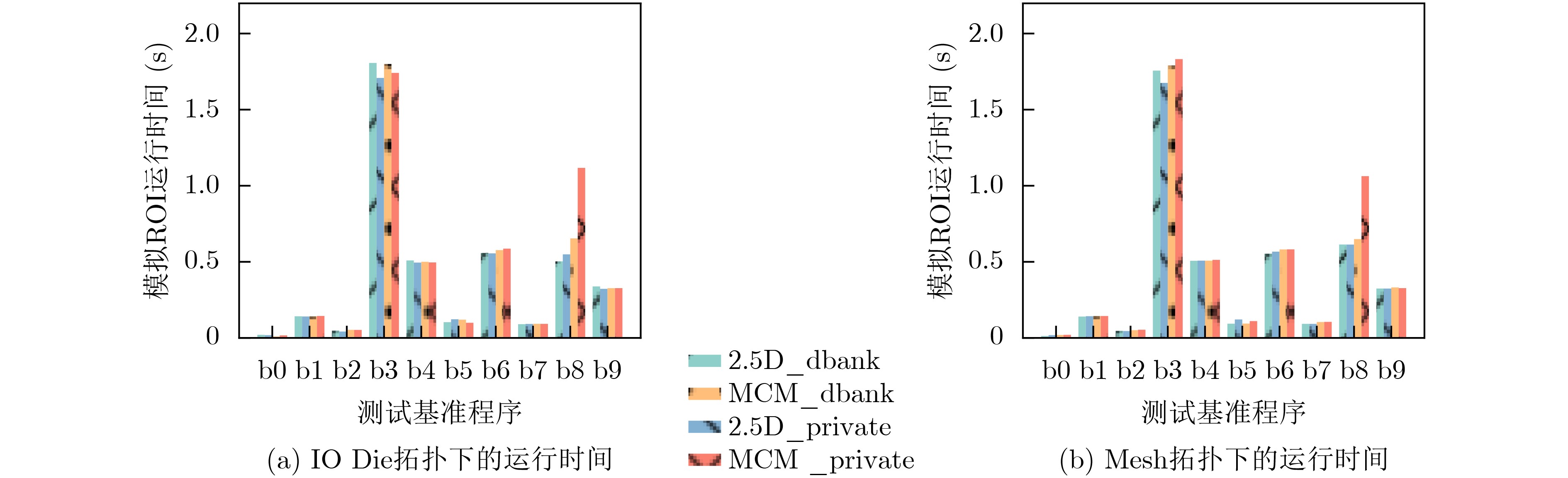
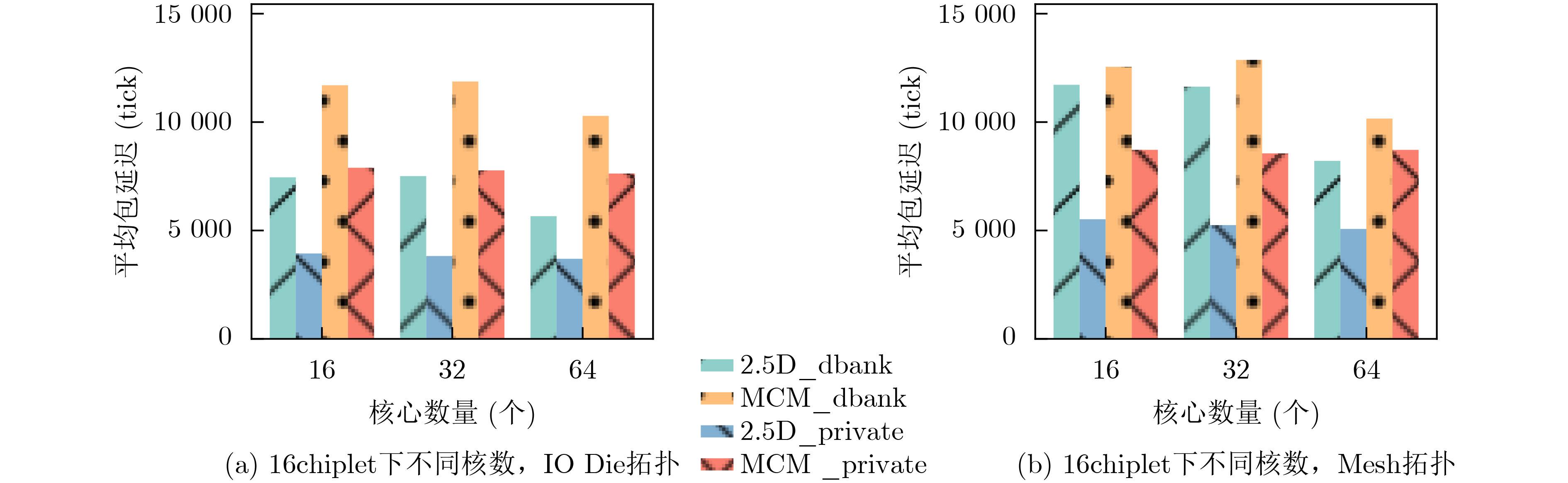
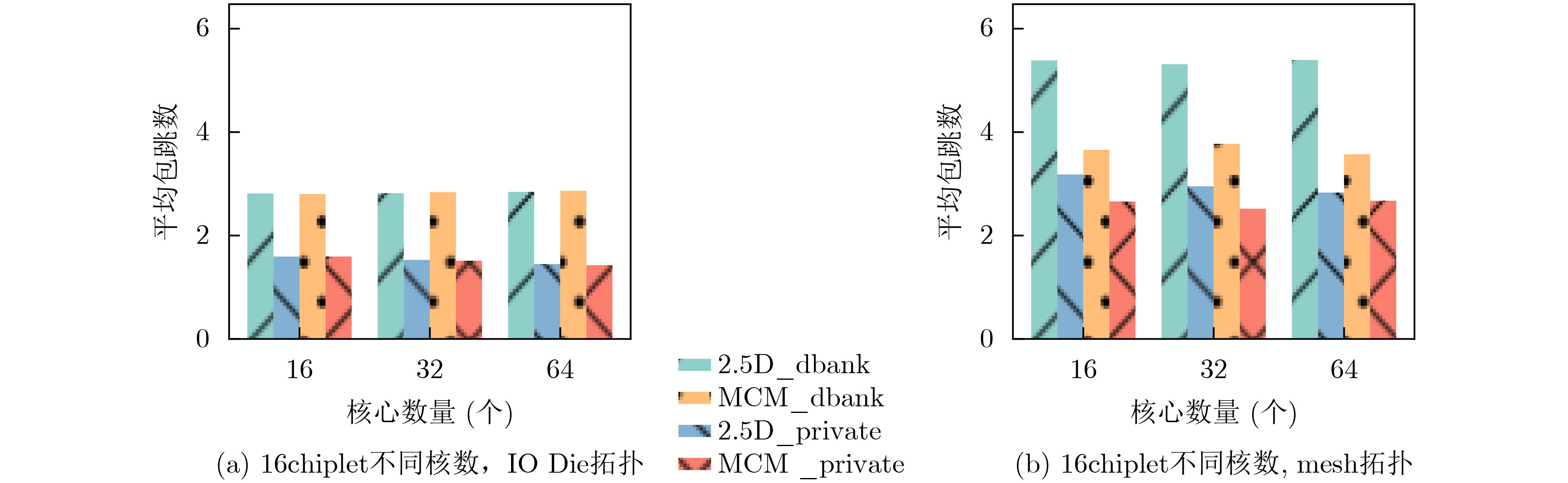
2024, 46(12): 4542-4552.
doi: 10.11999/JEIT240087
摘要:
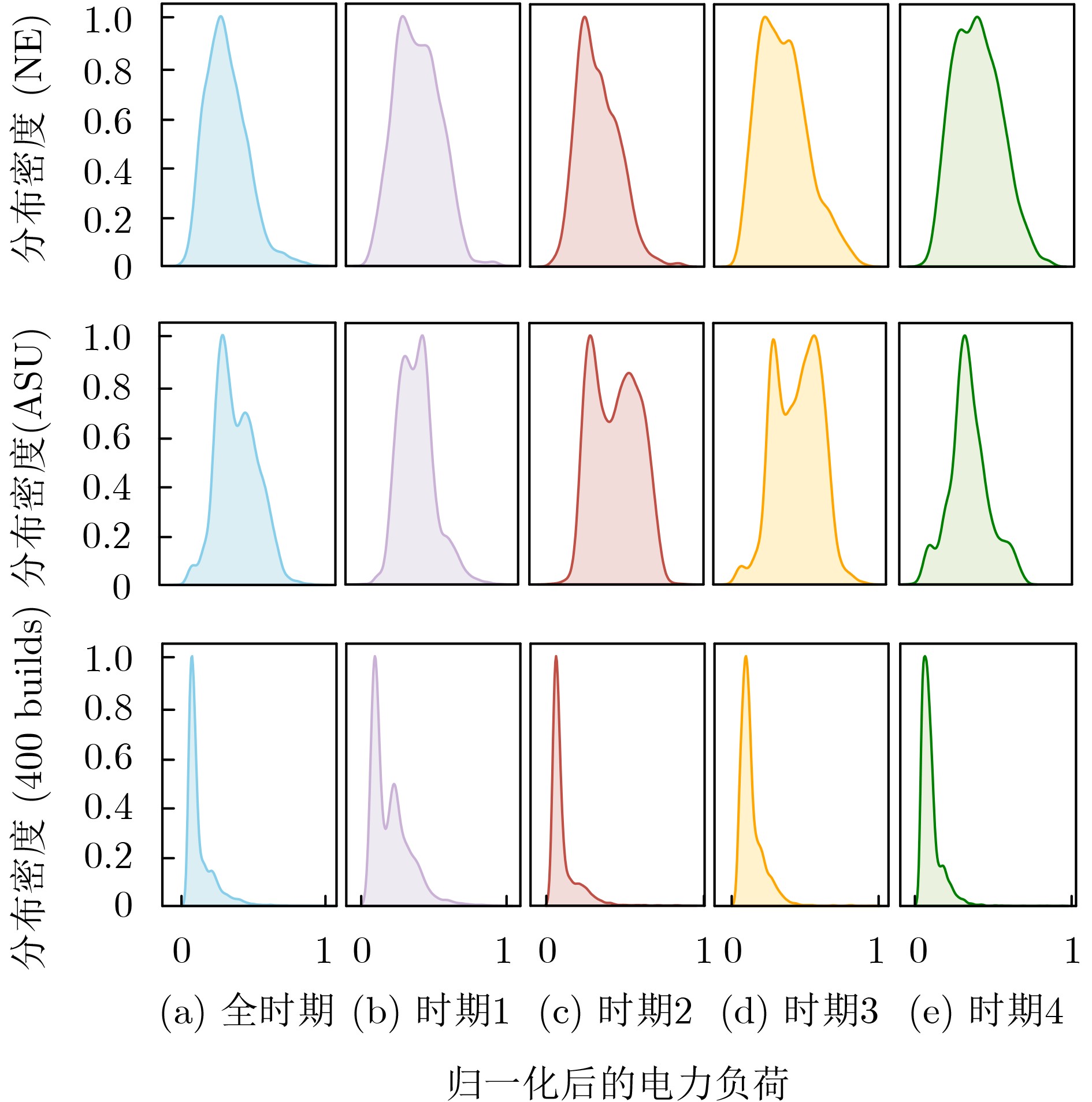
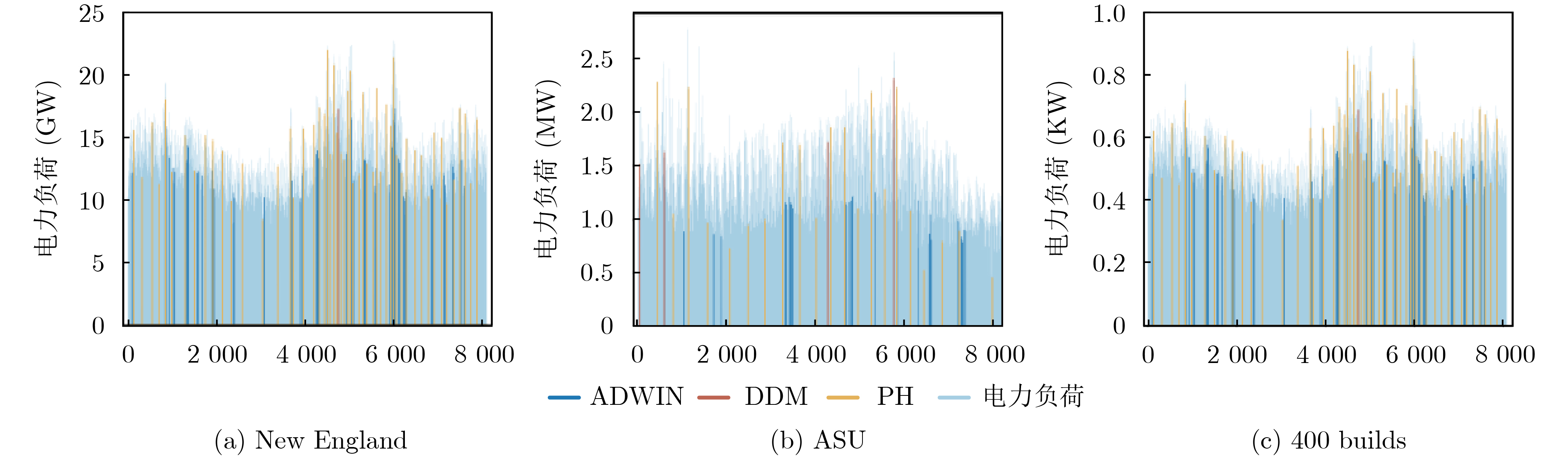
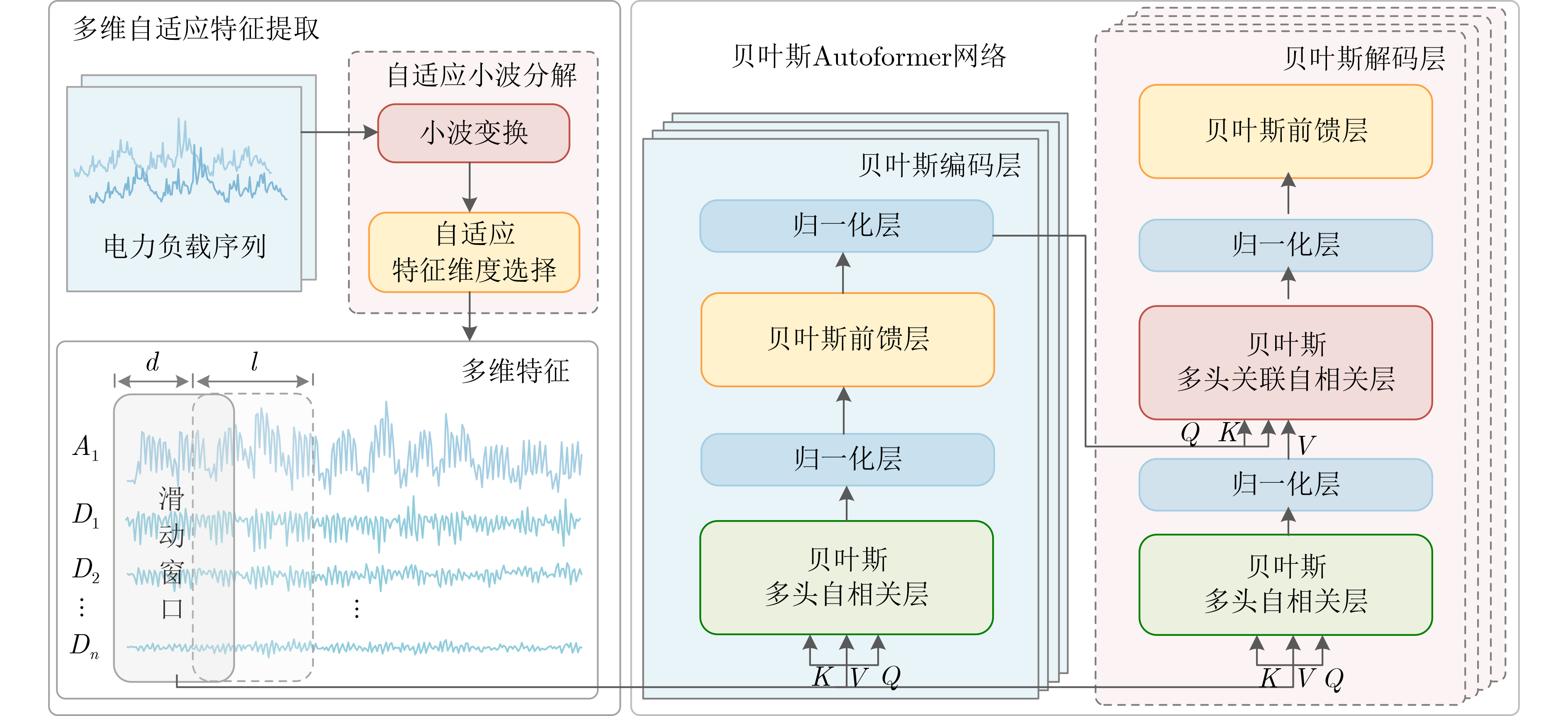
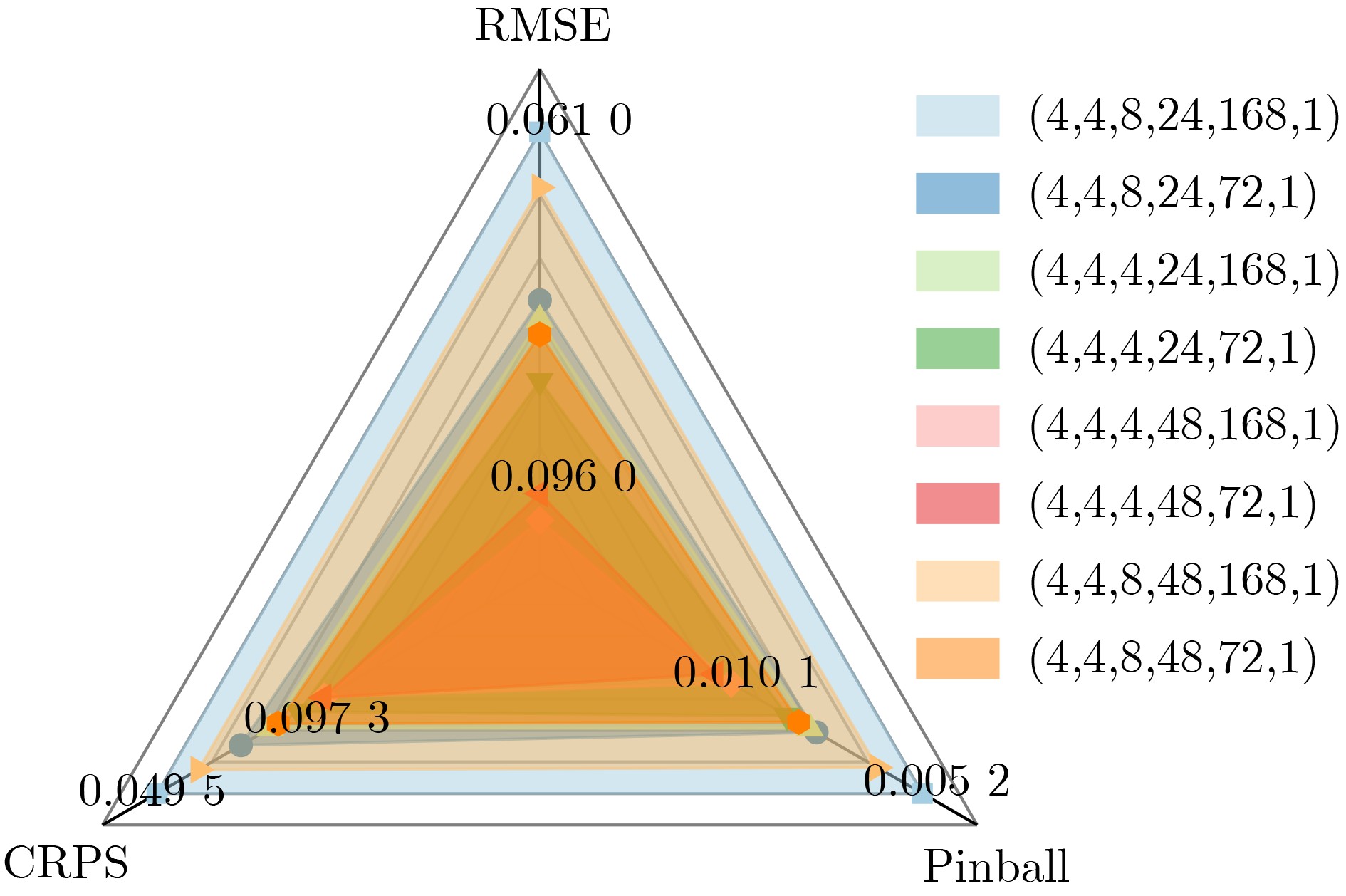
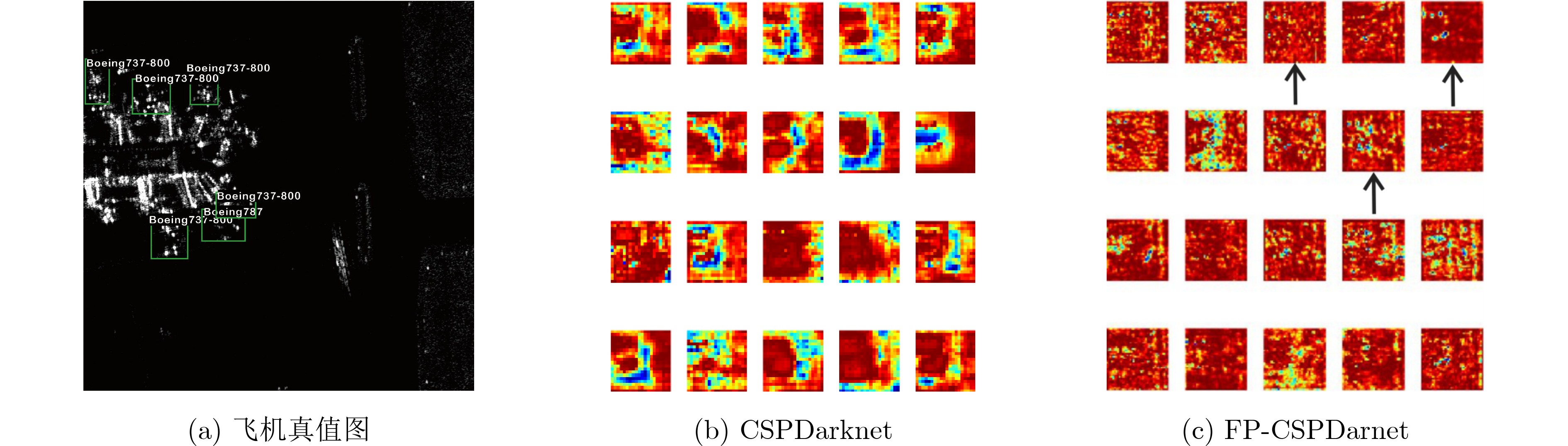
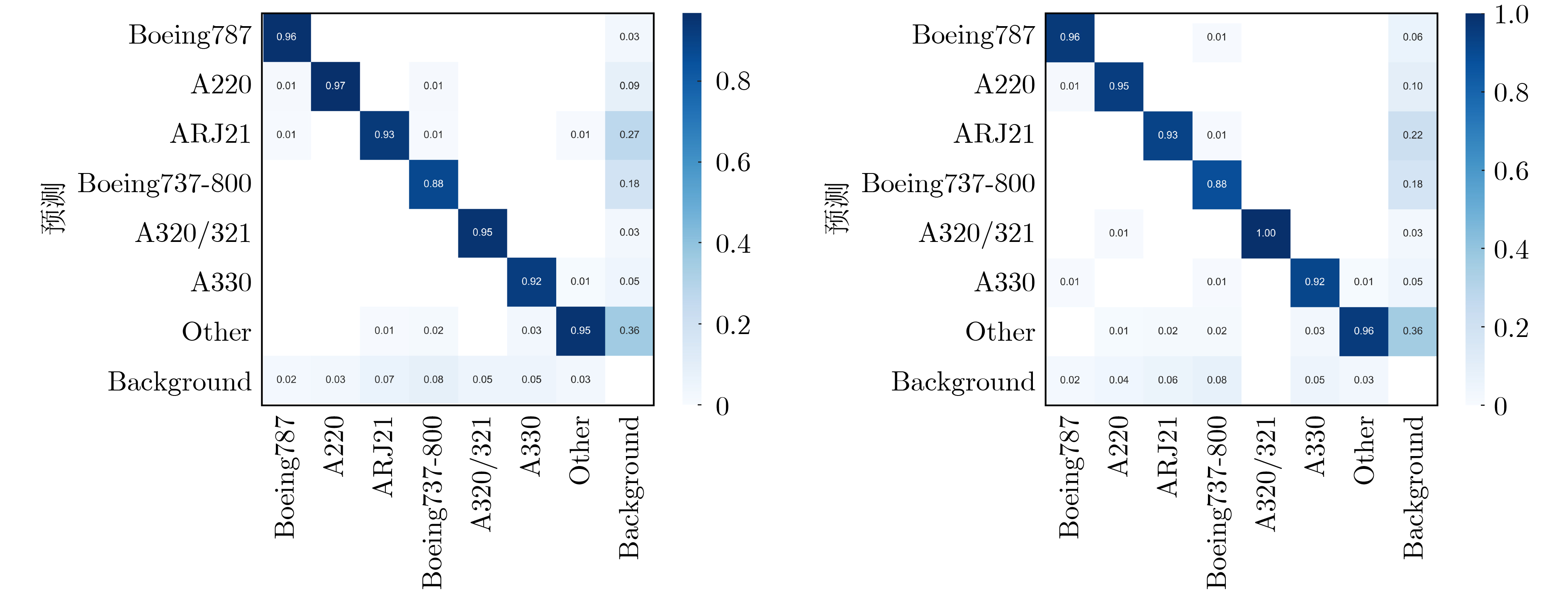
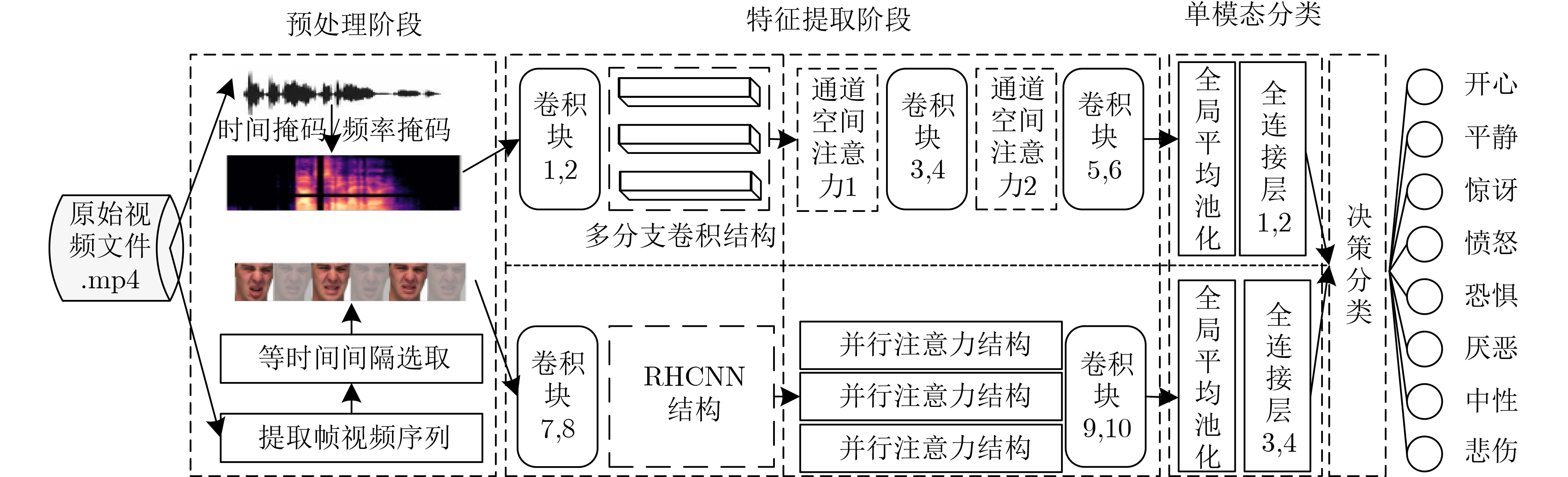
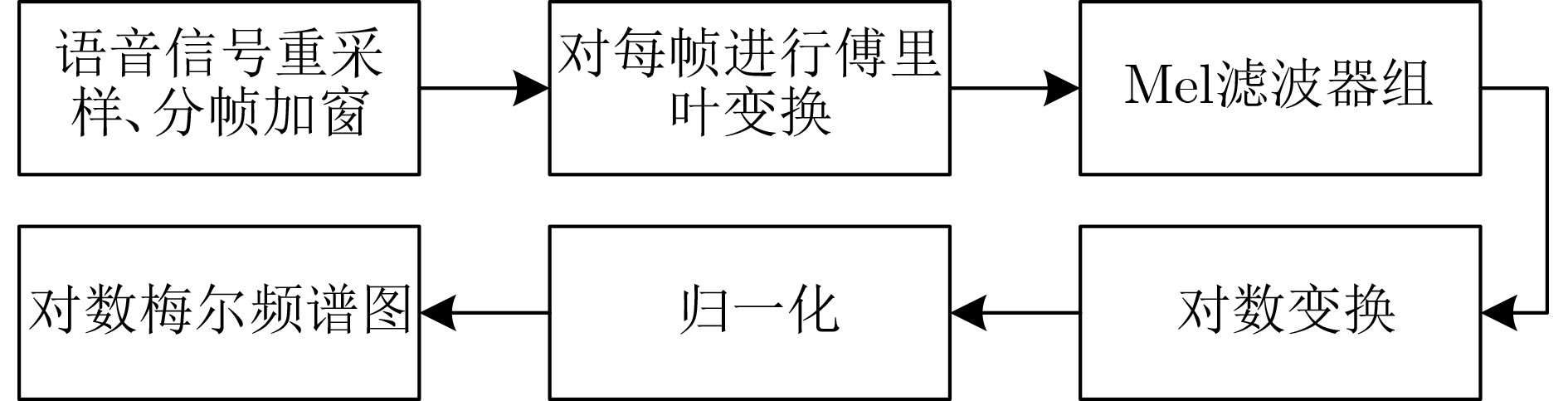
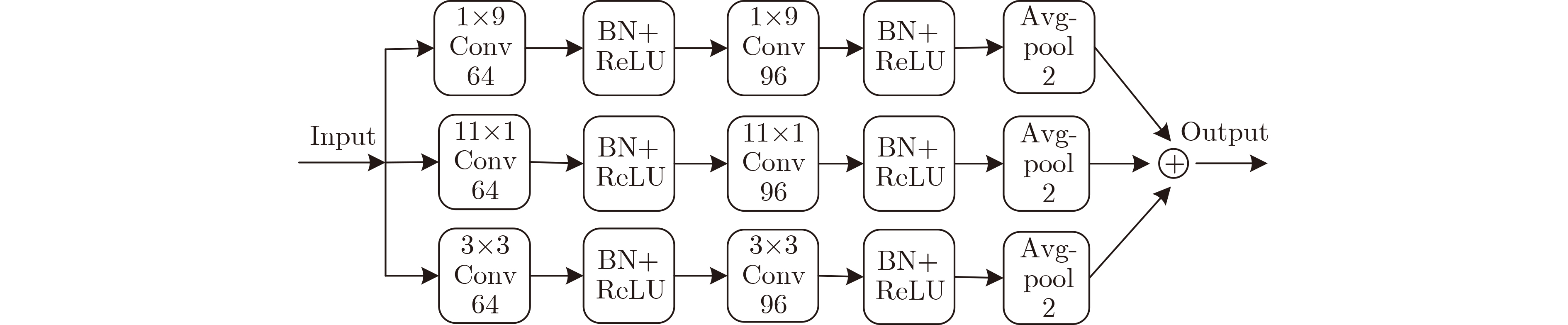
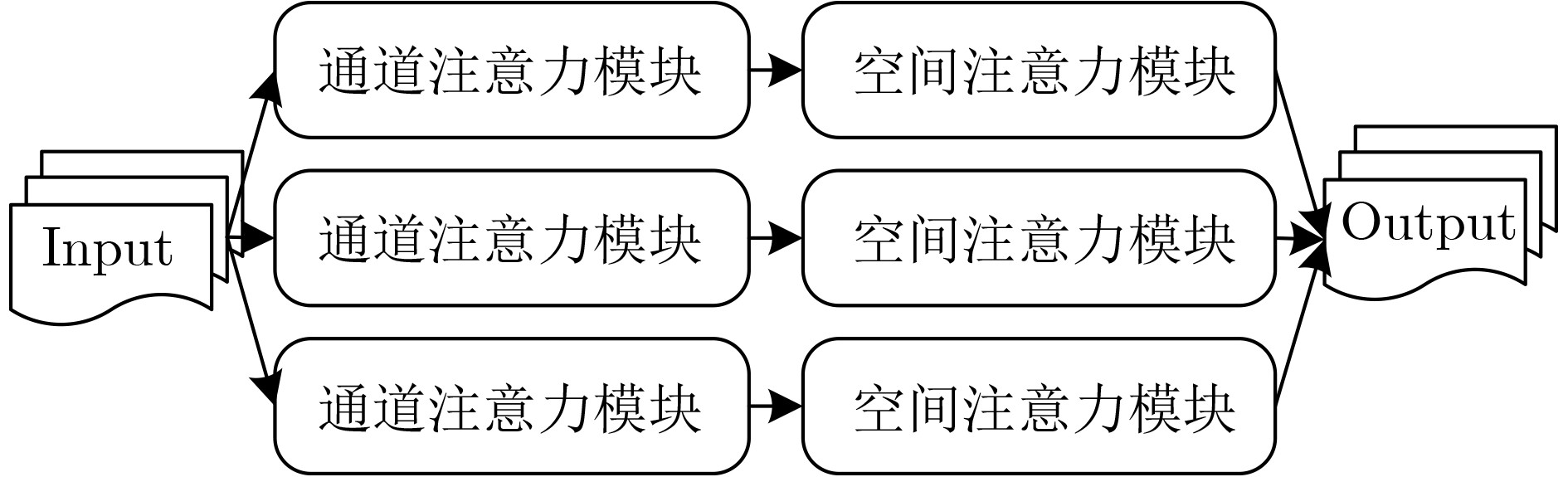
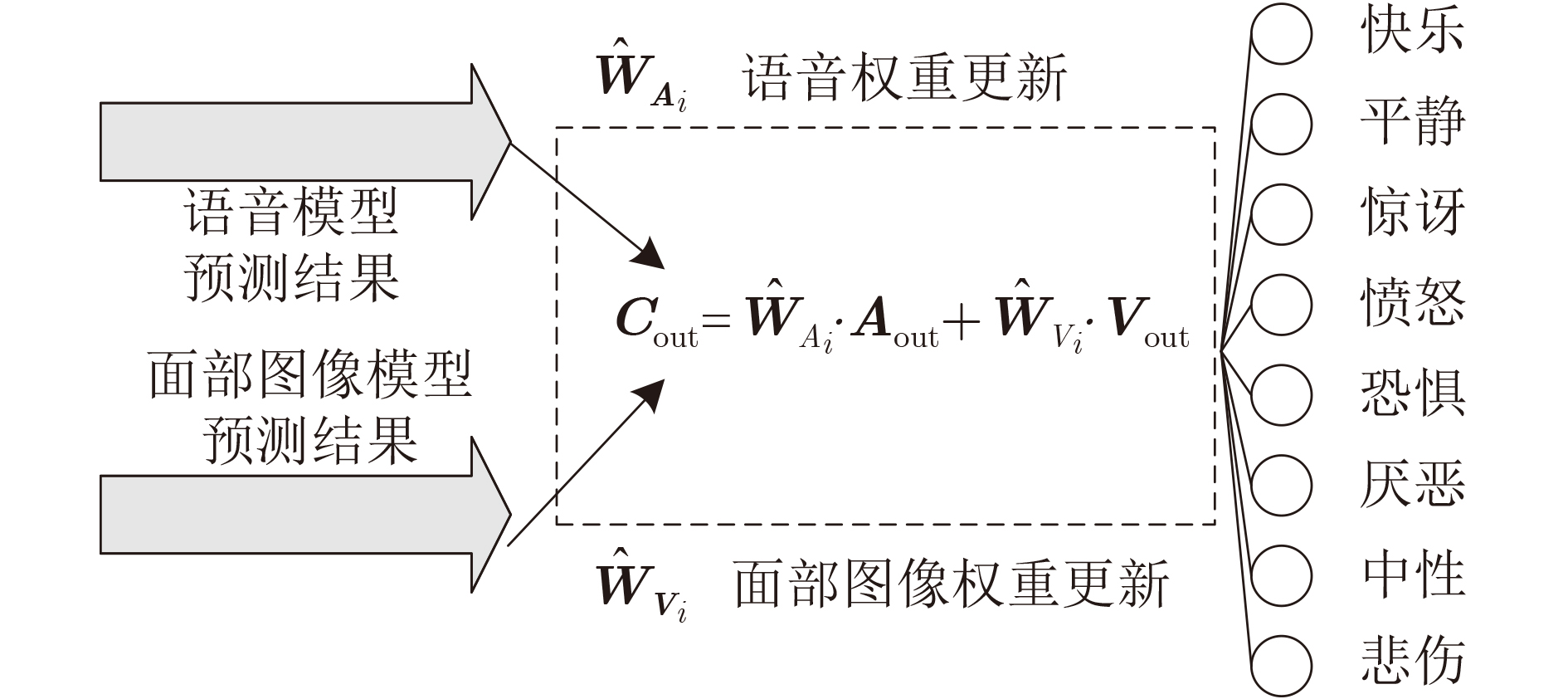
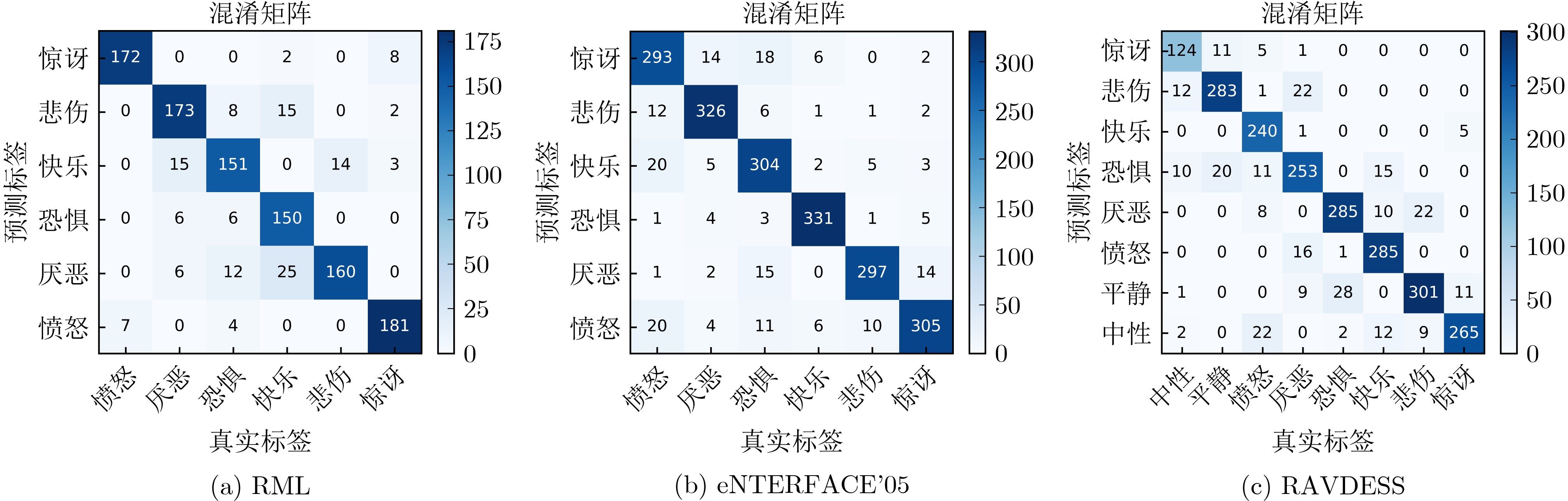
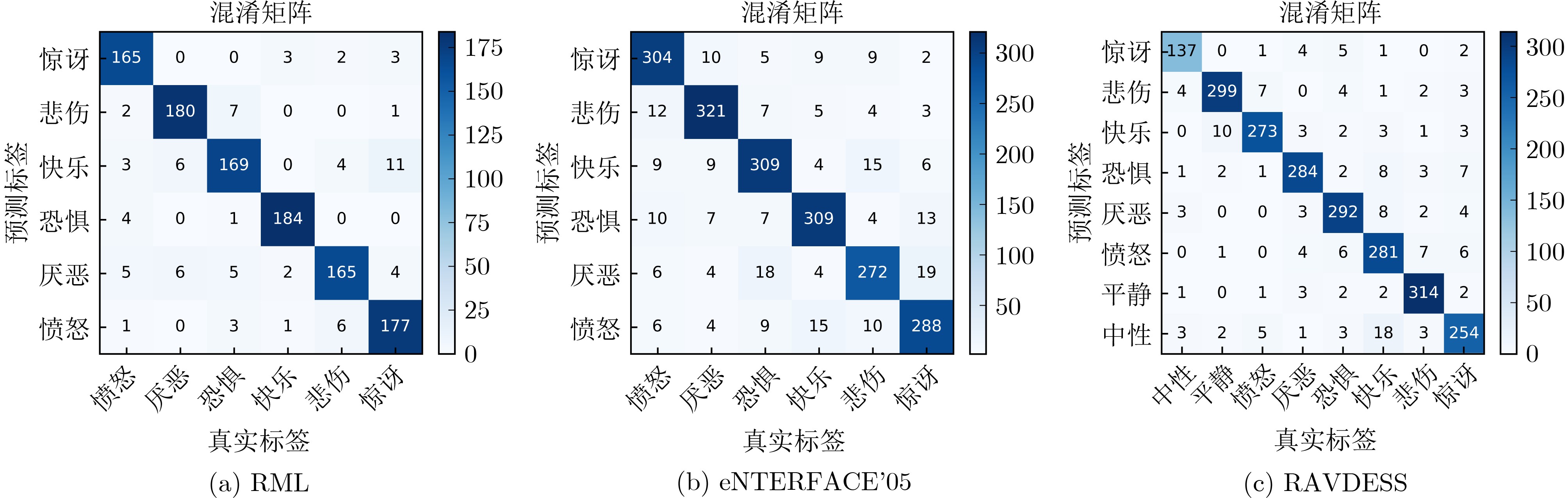
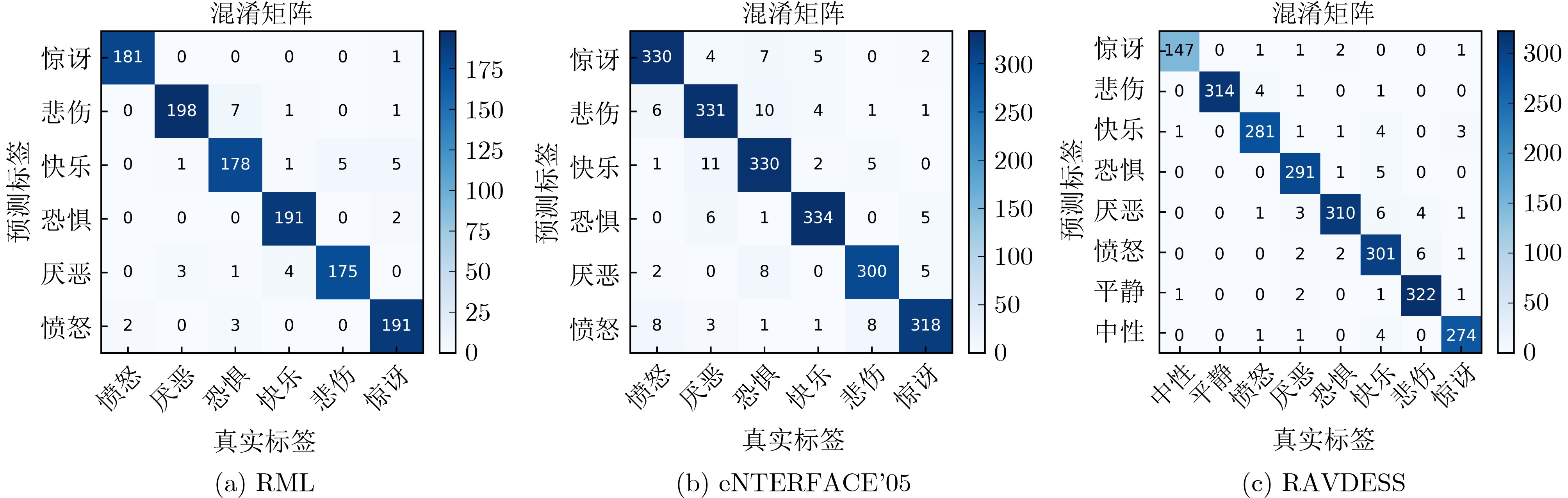
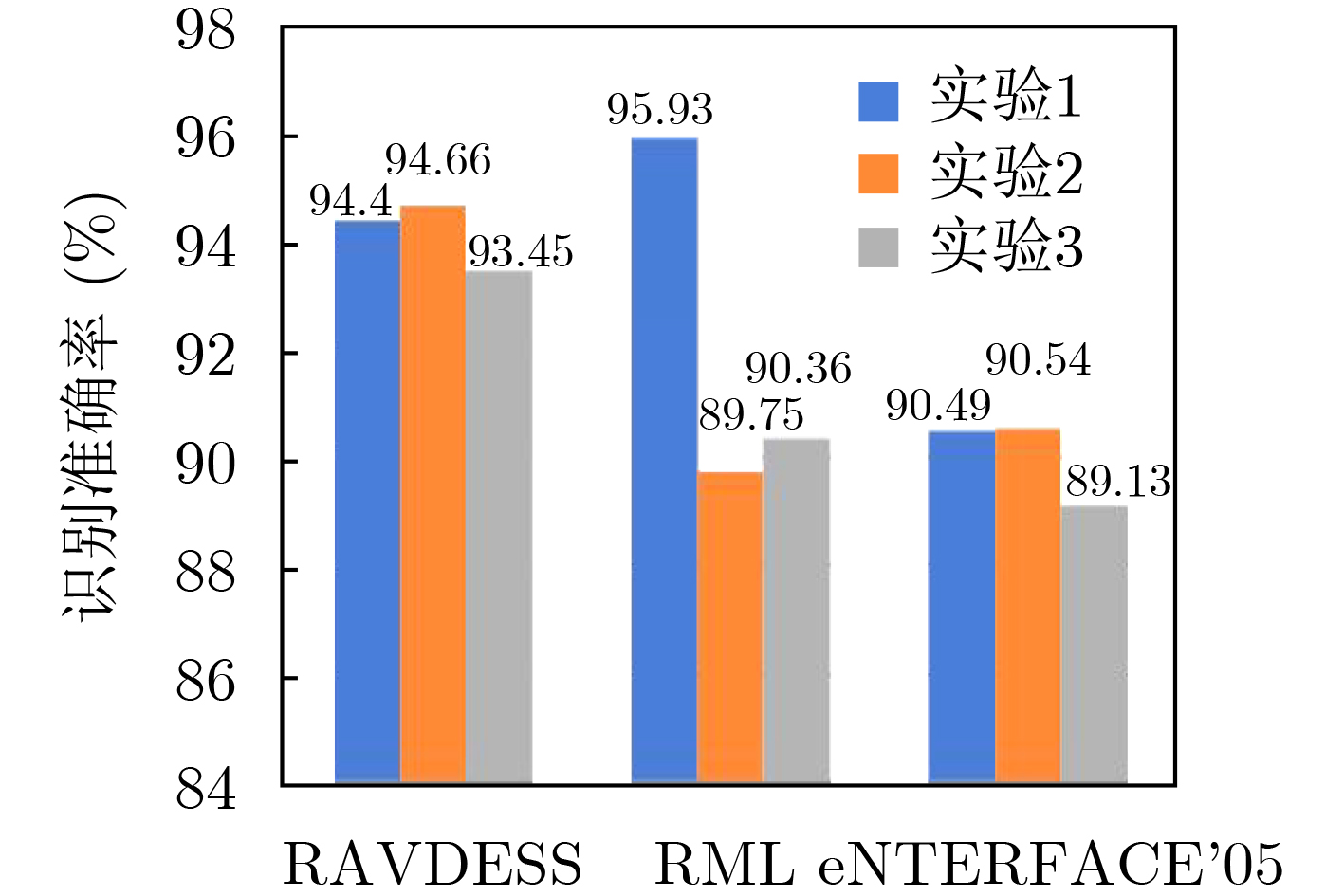
為提升情感識(shí)別模型的準(zhǔn)確率,解決情感特征提取不充分的問題�,對(duì)語音和面部圖像的雙模態(tài)情感識(shí)別進(jìn)行研究。語音模態(tài)提出一種結(jié)合通道-空間注意力機(jī)制的多分支卷積神經(jīng)網(wǎng)絡(luò)(Multi-branch Convolutional Neural Networks, MCNN)的特征提取模型�,在時(shí)間�����、空間和局部特征維度對(duì)語音頻譜圖提取情感特征��;面部圖像模態(tài)提出一種殘差混合卷積神經(jīng)網(wǎng)絡(luò)(Residual Hybrid Convolutional Neural Network, RHCNN)的特征提取模型�,進(jìn)一步建立并行注意力機(jī)制關(guān)注全局情感特征�����,提高識(shí)別準(zhǔn)確率��;將提取到的語音和面部圖像特征分別通過分類層進(jìn)行分類識(shí)別����,并使用決策融合對(duì)識(shí)別結(jié)果進(jìn)行最終的融合分類。實(shí)驗(yàn)結(jié)果表明�,所提雙模態(tài)融合模型在RAVDESS, eNTERFACE’05, RML三個(gè)數(shù)據(jù)集上的識(shí)別準(zhǔn)確率分別達(dá)到了97.22%, 94.78%和96.96%,比語音單模態(tài)的識(shí)別準(zhǔn)確率分別提升了11.02%, 4.24%, 8.83%�����,比面部圖像單模態(tài)的識(shí)別準(zhǔn)確率分別提升了4.60%, 6.74%, 4.10%���,且與近年來對(duì)應(yīng)數(shù)據(jù)集上的相關(guān)方法相比均有所提升�����。說明了所提的雙模態(tài)融合模型能有效聚焦情感信息���,從而提升情感識(shí)別的準(zhǔn)確率。